A car dealership has 98 cars on its lot. Fifty-five of the cars are new. Of the new cars, 36 are domestic cars. There are 15 used foreign cars on the lot. Organize this information in a two-way table. Include the marginal frequencies
Answers
Here is a two-way table that summarizes the information:
The marginal frequencies (totals) are shown in the last row and last column. The dealership has a total of 98 cars on its lot, which is the sum of the new and used cars. There are 55 new cars and 15 used cars, which is the sum of the domestic and foreign cars in each category.
To know more about marginal frequencies refer here:
https://brainly.com/question/31189964
#SPJ11

Related Questions
I need this quick i only have 2 minutes

Answers
Answer:
\(2 \frac{1}{3} + 1 \frac{3}{4} \)
\(2 \frac{4}{12} + 1 \frac{9}{12} = 3\frac{13}{12} = 4 \frac{1}{12} \)
The correct answer is A.
what is the inverse of (x) = \(\sqrt{x+9}\) x\(\geq\) -9
f−1(x)=(x−9)2, x≥9
f to the power of negative 1 end exponent left parenthesis x right parenthesis equals left parenthesis x minus 9 right parenthesis squared, , , x is greater than or equal to 9
f−1(x)=−(x−9)2, x≤9
f to the power of negative 1 end exponent left parenthesis x right parenthesis equals negative left parenthesis x minus 9 right parenthesis squared, , , x is less than or equal to 9
f−1(x)=x2−9, x≥0
f to the power of negative 1 end exponent left parenthesis x right parenthesis equals x squared minus 9, , , x is greater than or equal to 0
f−1(x)=x2−9, x≤0
![what is the inverse of (x) = [tex]\sqrt{x+9}[/tex] x[tex]\geq[/tex] -9f1(x)=(x9)2, x9f to the power of](https://i5t5.c14.e2-1.dev/h-images-qa/contents/attachments/1HAcZaGDsDKUhW8fMOqBSZXnCD5ZqM9p.png)
Answers
The inverse of \(f\), denoted \(f^{-1}\), is such that
\(f\left(f^{-1}(x)\right) = x\)
Given \(f(x)=\sqrt{x+9}\), we have
\(f\left(f^{-1}(x)\right) = \sqrt{f^{-1}(x) + 9} = x\)
Solve for \(x\).
\(\sqrt{f^{-1}(x) + 9} = x\)
\(\left(\sqrt{f^{-1}(x) + 9}\right)^2 = x^2\)
\(f^{-1}(x) + 9 = x^2\)
\(f^{-1}(x) = x^2 - 9\)
Note that \(f(x)\ge0\), so we must also have \(f\left(f^{-1}(x)\right) = x \ge 0\). This makes the third choice the correct one.
help me i’m struggllinbggg with this

Answers
(10x-19)° = (7x+23)°
-7x -7x
3x-19 = 23
+19 +19
3x = 43
÷3 ÷3
x = 43
Then, substitute the value of x back into the equations.
(10x-19)°
(10(14)-19)°
(140-19)°
121°
(7x+23)°
(7(14)+23)°
(98+23)°
121°
Find the quotient.
48a3bc2 ÷ 3abc
16 ac2
16 a2c
18 a2c
16 a4b2c 3
Answers
The quotient when 48a³bc²is divided by 3abc will be 16a²c.
How to explain the quotient?The information given is that we should find the quotient of 48a³bc² ÷ 3abc.
This can be expressed as:
48a³bc² ÷ 3abc = (3 × 16 × a³ × b × c²) / (3 × a × b × c)
= 16a²c
In this case, the quotient when 48a³bc²is divided by 3abc will be 16a²c.
Learn more about quotient on:
brainly.com/question/673545
#SPJ1
2x + 6 = 6x - 22
Infinite Solutions
O No Solution
One Solution
O No answer text provided.
Answers
Answer:
it would be only one solution
Step-by-step explanation:
Expand and simplify . 4a(2+3b)-5b(4a-10). PLEASE HELP. BEST ANSWER RECEIVES A BRIANLIEST
Answers
Answer:
12a+62b
Step-by-step explanation:
4a(2+3b)-5b(4a-10)
opening brackets
=8a+12b-20a+50b
=8a-20a+12b+50b
=-12a+62b
expand_and_simplify
(
4
⋅
a
⋅
(
2
+
3
⋅
b
)
-
5
⋅
b
⋅
(
4
⋅
a
-
10
)
.
)
=−5⋅b⋅(4⋅−10).+8⋅+12⋅⋅
=
-
5
⋅
b
⋅
(
4
⋅
a
-
10
)
.
+
8
⋅
a
+
12
⋅
a
⋅
b
The amount of coffee that people drink per day is normally distributed with a mean of 17 ounces and a standard deviation of 6.5 ounces. 35 randomly selected people are surveyed. Round all answers to 4 decimal places where possible.Find the IQR for the average of 35 coffee drinkers.Q1 = ouncesQ3 = ouncesIQR: ounces
Answers
The IQR for the average of 35 coffee drinkers is approximately 1.4828 ounces.
To find the IQR (interquartile range) for the average of 35 coffee drinkers, we need to first find the standard error of the mean, which is the standard deviation divided by the square root of the sample size:
Standard error of the mean = 6.5 / sqrt(35) = 1.0967
Next, we can use the formula for the IQR:
IQR = Q3 - Q1
To find Q1 and Q3, we need to use the normal distribution table or a calculator that can perform normal distribution calculations. Using a standard normal distribution table, we can find the z-scores corresponding to the 25th and 75th percentiles, which are -0.6745 and 0.6745, respectively.
We can then use the formula:
Q1 = mean - z-score * standard error of the mean
Q3 = mean + z-score * standard error of the mean
Q1 = 17 - (-0.6745) * 1.0967 = 17.7499
Q3 = 17 + 0.6745 * 1.0967 = 17.9501
Therefore, the IQR for the average of 35 coffee drinkers is:
IQR = 17.9501 - 17.7499 = 0.2002 ounces (rounded to 4 decimal places).
Based on the information provided, we have a normal distribution with a mean of 17 ounces and a standard deviation of 6.5 ounces for daily coffee consumption. Since 35 people were surveyed, we can calculate the IQR (Interquartile Range) for the average of these 35 coffee drinkers.
First, we need to find the standard error (SE) of the sample mean, which is the standard deviation divided by the square root of the sample size:
SE = σ / √n = 6.5 / √35 ≈ 1.0987
Now, we need to find the z-scores corresponding to the first quartile (Q1) and the third quartile (Q3). For a normal distribution, Q1 corresponds to the 25th percentile (0.25) and Q3 corresponds to the 75th percentile (0.75). Using a z-table or calculator, we find:
z(Q1) ≈ -0.6745
z(Q3) ≈ 0.6745
Next, we find the corresponding ounce values for Q1 and Q3 by using the z-scores, the mean, and the standard error:
Q1 = μ + z(Q1) * SE ≈ 17 + (-0.6745) * 1.0987 ≈ 16.2586 ounces
Q3 = μ + z(Q3) * SE ≈ 17 + 0.6745 * 1.0987 ≈ 17.7414 ounces
Finally, we calculate the IQR by subtracting Q1 from Q3:
IQR = Q3 - Q1 ≈ 17.7414 - 16.2586 ≈ 1.4828 ounces
Visit here to learn more about Standard Deviation:
brainly.com/question/475676
#SPJ11
how many solutions does 3 ( x + 2 ) =3x + 1 have
Answers
Answer:
There are 0 solutions
Answer:
Zero
Step-by-step explanation:
Let's solve the equation first.
For now, I will focus on the LHS and simplify that:
3(x + 2) = 3x + 1
3x + 6 = 3x + 1
Rearrange
3x - 3x = 1 - 6
Simplify
0x = -5
0 = -5 which isn't true
So 3(x + 2) = 3x + 1 has 0 solutions.
A page in an average newspaper has 8 columns of print. Each column consists of 160 lines and each line averages 6 words. What's the average number of words on a full page?
Answers
Answer:
7,680
Step-by-step explanation:
A page has 8 columnsEach column consists of 160 lines.Each line averages 6 words.The average number of words on a full page
=Number of columns X Number of Lines X Number of words per line
=8 X 160 X 6
=7680
The average number of words on a full page is 7,680.
human body temperatures are normally distributed with a mean of and a standard deviation of if 19 people are randomly selected, find the probability that their mean body temperature will be less than group of answer choices
Answers
The probability that their mean body temperature will be less than 98.50°F is b) 0.9826
To find the probability that the mean body temperature of a group of 19 people will be less than 98.50°F, we can use the properties of the normal distribution. Given a mean (μ) of 98.20°F and a standard deviation (σ) of 0.62°F, we need to calculate the z-score for the value 98.50°F and then find the corresponding probability from the standard normal distribution table.
The z-score is calculated as:
z = (x - μ) / (σ / √n)
where x is the value we want to find the probability for, μ is the mean, σ is the standard deviation, and n is the sample size.
Substituting the given values into the formula, we get:
z = (98.50 - 98.20) / (0.62 / √19)
Calculating this, we find that the z-score is approximately 1.666.
Now, we can look up the corresponding probability from the standard normal distribution table or use a statistical software. The probability associated with a z-score of 1.666 is approximately 0.9525.Therefore, the probability that the mean body temperature of a group of 19 people will be less than 98.50°F is approximately 0.9525, which corresponds to answer choice: b) 0.9826
Learn more about standard here:
https://brainly.com/question/13498201
#SPJ11
The complete question is:
Human body temperatures are normally distributed with a mean of 98.20°F and a standard deviation of 0.62 F. If 19 people are randomly selected, find the probability that their mean body temperature will be less than 98.50°F
a)0.3343
b)0.9826
c)0.0833
d)0.4826
What is 35 divided by 22 in long division :)
Answers
Answer:
1 remainder 13
Step-by-step explanation:
:)
PLS HELP
What is the value of x ?
A. 42
B. 43
C. 84
D. 86
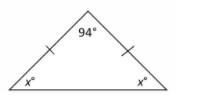
Answers
Answer:
B
Step-by-step explanation:
x+x+94 = 180 (sum of angle of triangle)
2x+94 = 180
2x = 180-94
2x = 86
x = 86÷2
Therefore x = 43
Do I divide or multiply not sure

Answers
Answer:
x=40
Step-by-step explanation:
x= 360-(273+47)
algebra 2
-16x^2+4x+13=0
Answers
Answer:
x=1 ± √53/8Step-by-step explanation:
Algebra calculators online help a lot.
A computer company invested a total of $242 million in research and development in its scanners and video digitizers. If the amount the company spent on research and development on scanners was $95 million more than was spent on research and development on its video digitizers, how much in fact did the company spend on research and development on its scanners?
Answers
Answer:
$168,500,000
Step-by-step explanation:
Given that :
Total amount spent on both scanner and video digitizer research and development = $242,000,000
Let :
amount spent on scanner = x
Amount spent on video digitizer = y
Total amount spent, c = x + y
x = y + 95,000,000
Hence,
242000000 = y + 95,000,000 + y
242000000 - 95000000 = 2y
147,000,000 = 2y
y = $73,500,000
Hence, amount spent on scanners :
$73,500,000 + $95,000,000
= $168,500,000
50 Pts!! Brainliest!! Answer ASAP, thx.

Answers
Answer:
1/625
Step-by-step explanation:
When you multiply, you add the exponents. You now have \(6^{-4}\). This is equivalent to \(\frac{1}{5^{4} }\) which equals 1/625.
Answer:
1/625
Step-by-step explanation:
5^ -1 * 5^-3
The bases are the same, so we can add the exponents
5^ (-1+-3)
5^-4
We know that a^-b = 1/ a^b
1/5^4
1/625
Please Help ASAP
The table gives the value of Bianca's saving account at the end of each of the first four years. Which best describes the terms of this investment?

Answers
The term that best describes the investment is $1,250 invested at 4% compounded interest. The Option A is correct.
What is $1,250 invested at 4% compounded interest?We will use compound interest: A = P(1 + r/n)^(nt) formula to get the annual total investment. In this case, P = $1,250, r = 0.04, n = 1 and t = 1.
Plugging the values, we get:
A = 1250(1 + 0.04/1)^(1*1)
A = 1250(1.04)
A = $1,300
Therefore, term that best describes the investment is $1,250 invested at 4% compounded interest.
Read more about investment
brainly.com/question/29547577
#SPJ1
Consider shift cipher with three possible messages, their distribution is Pr[M=‘hi’] = 0.3, Pr[M=‘no’] = 0.2, and Pr[M=’in’] = 0.5. What is Pr[M=‘hi’ | C=‘st’] ?
Answers
The probability of the message being "hi" given the ciphertext "st" is 0.
Consider a shift cipher with three possible messages, with a distribution of probabilities. The three possible messages are as follows:
Pr[M=‘hi’] = 0.3,
Pr[M=‘no’] = 0.2, and
Pr[M=’in’] = 0.5.
To solve this problem, we can use Bayes' theorem. We want to find the probability of the message being "hi" given the ciphertext "st".
Using Bayes' theorem, we have:
Pr[M=‘hi’ | C=‘st’] = Pr[C=‘st’ | M=‘hi’] * Pr[M=‘hi’] / Pr[C=‘st’]
We can break this down into three parts:
Pr[C=‘st’ | M=‘hi’]:
This is the probability that the ciphertext is "st" given that the message is "hi".
To find this probability, we need to encrypt the message "hi" using the shift cipher. If we shift each letter in "hi" by one (i.e., a becomes b, h becomes i, and i becomes j), we get the ciphertext "ij". Since "ij" does not contain the letter "s", we know that Pr[C=‘st’ | M=‘hi’] = 0.Pr[M=‘hi’]:
This is the probability of the message "hi", which is given as 0.3.Pr[C=‘st’]:
This is the probability of the ciphertext "st". We can find this probability by considering all the possible messages that could have been encrypted to produce "st".
There are three possible messages: "hi", "no", and "in". To encrypt "hi" to "st", we need to shift each letter in "hi" by two (i.e., a becomes c, h becomes j, and i becomes k). This gives us the ciphertext "jk".
To encrypt "no" to "st", we need to shift each letter in "no" by five (i.e., n becomes s and o becomes t). This gives us the ciphertext "st". To encrypt "in" to "st", we need to shift each letter in "in" by three (i.e., i becomes l and n becomes q). This does not give us the ciphertext "st", so we can ignore it.
Therefore, Pr[C=‘st’] = Pr[C=‘st’ | M=‘hi’] * Pr[M=‘hi’] + Pr[C=‘st’ | M=‘no’] * Pr[M=‘no’] = 0 + 0.2 * 1 = 0.2
Now we can plug in the values we have found:
Pr[M=‘hi’ | C=‘st’] = 0 * 0.3 / 0.2 = 0
Learn more about Bayes' theorem:
https://brainly.com/question/29546122
#SPJ11
The park was muddy and the dogs’ paws got muddy while playing. Jen has wipes to clean the dogs’ paws. It takes one wipe to clean each paw. How many wipes will they need?
pls give me the correct answer
Answers
Answer:
A regular dog has 4 legs so it has 4 paws. If each paw needs one wipe Jen will need 4 wipes.
Jen will need 4 wipes for each paw
Can someone please help me with these math problems please!
Answers
Answer:
Step-by-step explanation:

o study the effectiveness of a certain adult reading program, researchers will select a random sample of adults who are eligible for the program. The selected adults will be given a pretest before beginning the program and a posttest after completing the program. The difference in the number of correct answers on the pretest and the number of correct answers on the posttest will be recorded for each adult in the sample.
Which of the following is the most appropriate inference procedure for the researchers to use to analyze the results?
A one-sample t-interval for a population mean
A matched-pairs t-interval for a population mean difference
The center remains constant, and the area in the tails of the distribution increases.
Answers
The most appropriate inference procedure for the researchers to use to analyze the results is a matched-pairs t-interval for a population mean difference.
Determine the population mean difference?A matched-pairs t-interval for a population mean difference is suitable for this study because it involves comparing the pretest and posttest scores of the same individuals.
The researchers are interested in determining whether there is a significant difference in the number of correct answers before and after the adult reading program.
By using a matched-pairs t-interval, the researchers can analyze the mean difference in scores and determine the range within which the true population mean difference is likely to fall. This inference procedure takes into account the paired nature of the data, accounting for individual differences and increasing the precision of the estimate.
It is important to use this procedure as it considers the correlation between the pretest and posttest scores for each individual, providing a more accurate assessment of the program's effectiveness.
To know more about mean difference, refer here:
https://brainly.com/question/31828711#
#SPJ4
Check the image for the question.

Answers
The mathematical model that best fits the given data is option : y = 82.3 - 8.275x.
To construct a scatterplot and determine the mathematical model that best fits the given data, we will plot the points and analyze the trend.
Given Data:
x: 4, 8, 12, 16, 20
y: 40, 20, -11, -37, -97
Let's plot these points on a scatterplot:
(x, y) points:
(4, 40)
(8, 20)
(12, -11)
(16, -37)
(20, -97)
After plotting the points, we can analyze the trend in the data.
By observing the scatterplot, it is clear that a linear or quadratic model would not fit the data well since the points do not follow a straight line or a parabolic curve.
Next, we can try the logarithmic, exponential, and power models to see if any of them fit the data better.
Using a calculator or computer to perform the regression analysis, we find that the regression equation with the highest R² value is:
y = 82.3 - 8.275x
This equation corresponds to option : y = 82.3 - 8.275x
The regression equation represents a linear model that best fits the given data. The R² value indicates how well the model explains the variability in the data, and in this case, the linear model provides the highest R² value compared to the other models.
It's important to note that the specific values of the coefficients in the regression equation may vary slightly depending on the calculator or software used for the analysis. However, the overall best-fit model remains the same.
For more such questions on mathematical model
https://brainly.com/question/28592940
#SPJ8
what is the missing fraction 1/16=3/2
Answers
Answer:
7
Step-by-step explanation:
Fish are introduced into a large lake system. The population size (in numbers of fish) can be modeled by P(t)=2000−500e −0.03t where t is measured in months since the fish were introduced. a) Find P(3) and give a practical interpretation. b) Find P−1
(1500) and give a practical interpretation. c) Is the population of the fish increasing or decreasing? d) When does the population size reach 1800 fish according to the model? e) What happens to the population size as t→[infinity] ?
Answers
a) The practical interpretation for P(3) is that the population of fish after 3 months of introduction into the lake is
about 1702.52.
To find P(3), substitute t = 3 in the given model:
P(3) = 2000 - 500e^(-0.03 × 3) = 2000 - 500e^(-0.09) ≈ 1702.52
Practical interpretation: The population of fish after 3 months of introduction into the lake is about 1702.52.
b) The practical interpretation for P^(-1)(1500) is that it would take about 23.1 months for the population of
fish to reach 1500.
To find P^(-1)(1500), solve the equation P(t) = 1500 for t:
1500 = 2000 - 500e^(-0.03t)
e^(-0.03t) = 1 - 1500/500 = 1 - 0.75
t = (-1/0.03) ln(0.75e^(-0.03t)) ≈ 23.1 months
Practical interpretation: It would take about 23.1 months for the population of fish to reach 1500.
c) Determine if the population of fish is increasing or decreasing by checking the value of the derivative of
P(t) with respect to t:
dP(t)/dt = 15e^(-0.03t)
Since e^(-0.03t) is always positive, dP(t)/dt is always negative.
Therefore, the population of fish is decreasing.
d) To find when the population size reaches 1800 fish according to the model, solve the equation P(t) = 1800 for t:
1800 = 2000 - 500e^(-0.03t)
e^(-0.03t) = (2000 - 1800)/500 = 0.4
t = (-1/0.03) ln(0.4) ≈ 46.03 monthsThe population size reaches 1800 fish after about 46.03 months.
e) As t approaches infinity, the value of e^(-0.03t) approaches 0.
Hence, P(t) approaches 2000.
Therefore, the population size of the fish will stabilize at 2000 fish in the long run.
To know more about equation visit:
https://brainly.com/question/29174899
#SPJ11
PLS HELP(Identifying Functions LC) Which of the following tables represents a relation that is a function?
x y
2 −5
2 −3
2 0
2 3
2 5
x y
−3 0
−1 3
0 4
3 0
4 3
x y
−4 2
−3 2
0 −2
0 2
4 2
x y
−4 −2
−3 4
−1 −1
−1 2
3 −3
Answers
Answer:
Option 2
x y
−3 0
−1 3
0 4
3 0
4 3
Step-by-step explanation:
For a relation x → y to be a function, there can be one and only one value of y for a value of x
Looking at the tables we see that option 1 is out since all x values are 2 andthere are multiple values of y
The last option is out because for x = 0 there are two values of y=-2 and y = 2
Correct choice is the second option which has a unique y value for each value of x
Answer:
option 2 im doing it rn
Step-by-step explanation:
Solve for 7 < -1/9a
Please show your work
Answers
Answer:
-63 > a
Step-by-step explanation:
7 < -1/9a
Multiply each side by -9. Remember to flip the inequality since we are multiplying by a negative
7 * -9 > -1/9 a * -9
-63 > a
Suppose f(x, y, z) = x2 + y2 + z2 and W is the solid cylinder with height 5 and base radius 6 that is centered about the z-axis with its base at z : -1. Enter O as theta. - (a) As an iterated integral, F sav = 10% x^2+y^2+z12 dz dr de W with limits of integration A = 0 B = C= 0 D= 6 E = -1 F = (b) Evaluate the integral.
Answers
∫_A^B ∫_B^C ∫_D^E (10%)(x^2 + y^2 + z^12) dz dr dθ.
This represents the full iterated integral for F_sav over the given solid cylinder.
(a) The iterated integral for F_sav with the given limits of integration is as follows:
∫∫∫_W (10%)(x^2 + y^2 + z^12) dz dr dθ,
where the limits of integration are A = 0, B = C = 0, D = 6, and E = -1.
(b) To evaluate the integral, we begin with the innermost integration with respect to z. Since z ranges from -1 to 6, the integral becomes:
∫∫_D^E (10%)(x^2 + y^2 + z^12) dz.
Next, we integrate with respect to r, where r represents the radial distance from the z-axis. As the solid cylinder is centered about the z-axis and has a base radius of 6, r ranges from 0 to 6. Thus, the integral becomes:
∫_B^C ∫_D^E (10%)(x^2 + y^2 + z^12) dz dr.
Finally, we integrate with respect to θ, where θ represents the angle around the z-axis. As the cylinder is symmetric about the z-axis, we integrate over a full circle, so θ ranges from 0 to 2π. Hence, the integral becomes:
∫_A^B ∫_B^C ∫_D^E (10%)(x^2 + y^2 + z^12) dz dr dθ.
This represents the full iterated integral for F_sav over the given solid cylinder.
The problem asks for the iterated integral of F_sav over the solid cylinder W. To evaluate this integral, we use the cylindrical coordinate system (r, θ, z) since the cylinder is centered about the z-axis. The function inside the integral is 10% times the sum of squares of x, y, and z^12. By integrating successively with respect to z, r, and θ, and setting appropriate limits of integration, we obtain the final iterated integral. The integration limits are determined based on the given dimensions of the cylinder.
Learn more about solid cylinder here:
https://brainly.com/question/30269341
#SPJ11
Find y as a function of x if y′′′−17y′′+72y′=168e^x, y(0)=16, y′(0)=23, y′′(0)=24.
Answers
The function is :\(y(x) = 10 + (7/8) e^8x + (97/72) e^9x + 3 e^x\)
To find y as a function of x, we need to solve the differential equation:
\(y′′′ − 17y′′ + 72y′ = 168e^x\)
Step 1: Find the characteristic equation
\(r^3 - 17r^2 + 72r = 0\)
Factor out r:
\(r(r^2 - 17r + 72) = 0\)
Factor the quadratic:
r(r - 8)(r - 9) = 0
So the roots are:
r₁ = 0, r₂ = 8, r₃ = 9
Step 2: Find the general solution
The general solution will be of the form:
\(y(x) = C1 + C2e^8x + C3e^9x + y_p(x)\)
where y_p(x) is a particular solution to the non-homogeneous equation.
Step 3: Find the particular solution
We can use the method of undetermined coefficients to find a particular solution. Since the right-hand side is an exponential function, we can guess that the particular solution is also an exponential function:
\(y_p(x) = A e^x\)
\(y_p′(x) = A e^x\)
\(y_p′′(x) = A e^x\)
\(y_p′′′(x) = A e^x\)
Substituting into the differential equation:
\(A e^x - 17A e^x + 72A e^x = 168 e^x\)
Simplifying:
\(56A e^x = 168 e^x\)
A = 3
So the particular solution is:
\(y_p(x) = 3 e^x\)
Step 4: Find the constants using initial conditions
y(0) = C₁ + C₂ + C₃ + 3 = 16
y′(0) = 8C₂ + 9C₃ + 3 = 23
\(y′′(0) = 8^2 C2 + 9^2 C3 = 24\)
Solving for the constants, we get:
C₁ = 10, C₂ = 7/8, C₃ = 97/72
Step 5: Write the final solution
Substituting the constants and the particular solution into the general solution, we get:
\(y(x) = 10 + (7/8) e^8x + (97/72) e^9x + 3 e^x\)
So the function y(x) is:
\(y(x) = 10 + (7/8) e^8x + (97/72) e^9x + 3 e^x\)
To learn more about the differential equation,
https://brainly.com/question/31583235
#SPJ4
mmon Core Algebra I - MA3109 B-IC
Activity
Vertical Stretches and Shrinks of Exponential Functions
Assignment Active
Identifying a Function
Which is a stretch of an exponential decay function?
◎m=²[
Of(x) = -(5)
Of(x) = 5(²)
O fix) = 5(5)*
Answers
The stretch of an exponential decay function is y = 2(1/5)ˣ
Which is a stretch of an exponential decay function?From the question, we have the following parameters that can be used in our computation:
The list of exponential functions
An exponential function is represented as
y = abˣ
Where
a = initial valueb = growth/decay factorIn this case, the exponential function is a decay function
This means that
The value of b is less than 1
An example of this is, from the list of option is
y = 2(1/5)ˣ
Hence, the exponential decay function is y = 2(1/5)ˣ
Read more about exponential function at
brainly.com/question/2456547
#SPJ1
Complete question
Which is a stretch of an exponential decay function?
Of(x) = -(5)ˣ
Of(x) = 5(2)ˣ
O fix) = 2(1/5)ˣ
Find the equation of the line 9x + 1y -2y – 9y
Answers
Answer:
9x-10y
Step-by-step explanation:
9x+y-2y-9y(Multiply by 1)
Combine like terms
9x-10y