A study is designed to test the hypotheses h0: m $ 26 versus ha: m , 26. a random sample of 50 units was selected from a specified population, and the measurements were summarized to y 5 25.9 and s 5 7.6. a. with a 5 .05, is there substantial evidence that the population mean is less than 26
Answers
The p-value for a t-score of -0.92 is approximately 0.18 and since it is greater than the significant level, the null hypothesis is rejected.
The first step in testing this hypothesis is to calculate the test statistic, which in this case is a t-score. The formula for the t-score is (y - mu) / (s / sqrt(n)), where y is the sample mean, mu is the hypothesized population mean, s is the sample standard deviation, and n is the sample size.
In this case, the sample mean is 25.9, the hypothesized population mean is 26, the sample standard deviation is 7.6, and the sample size is 50. Plugging these values into the formula, we get a t-score of -0.92.
Next, we need to find the p-value associated with this t-score. We can use a t-table or a calculator to do this. Using a t-table with 49 degrees of freedom (since we have a sample size of 50 and one parameter estimated from the sample), we find that the p-value for a t-score of -0.92 is approximately 0.18.
Since the p-value is greater than the significance level of 0.05, we fail to reject the null hypothesis. In other words, we do not have substantial evidence to conclude that the population mean is less than 26. However, it is important to note that the sample mean is slightly below the hypothesized population mean, and the p-value is relatively close to the significance level. Therefore, it may be worthwhile to conduct additional studies with larger sample sizes or different populations to further investigate this question.
Know more about null hypothesis here:
https://brainly.com/question/19263925
#SPJ11
Related Questions
I need the value of x with an explanation

Answers
The value of x if The measure of the angle is = 5x + 4, The measure of the angle is = 146, The lines are parallel, is 6.
What are parallel lines?Parallel lines are any two or more lines that all lie in the same plane and never cross one another. They are equally spaced apart and have the same incline.
Given:
The measure of the angle is = 5x + 4
The measure of the angle is = 146
The lines are parallel,
Calculate the value of x as shown below,
5x + 4 = 180 - 146 (Parallel line theorem, corresponding angle, and supplementary angles)
5x = 34 - 4
x = 30 / 5
x = 6
Thus, the value of x is 6.
To know more about parallel lines:
https://brainly.com/question/29762825
#SPJ1
how did we get value 0.0004?
Answers
Unfortunately, without more context about the origin of the value 0.0004, it is not possible to provide a detailed explanation of how it was obtained. The method for obtaining this value will depend on the context in which it is used.
For example, if 0.0004 is a decimal fraction, it may have been obtained by dividing a small number by a larger number. If it is a monetary amount, it may have been the result of a calculation involving currencies, exchange rates, or taxes. If it is a measurement of physical quantity, it may have been obtained using a scale, ruler, or other measuring device.
The value 0.0004 can have different meanings depending on the context in which it is used. For example, it could represent a decimal fraction, a monetary amount, or a measurement of physical quantity.
Here you can learn more about decimal fraction
https://brainly.com/question/29116962#
#SPJ11
Answer:
Step-by-step explanation:
Which one of the following statements is not true concerning PivotTables in Excel? O a. PivotTables are also known as crosstabulation tables. b. PivotTables summarize data for two variables. c.PivotTables can be built using data arrayed in rows. d. PivotTables are interactive.
Answers
The statement that is not true concerning PivotTables in Excel is b. PivotTables summarize data for two variables. PivotTables can summarize data for multiple variables, not just two.
PivotTables allow you to analyze and summarize data from various perspectives, including multiple variables, by grouping, filtering, and calculating values based on different criteria. They provide flexibility in summarizing and organizing data in a tabular format, making it easier to extract insights and perform data analysis efficiently.
To know more about Pivot table, visit:
https://brainly.com/question/29817099
#SPJ11
Devaughn earns $7.25 per hour working as a waiter at TGI Fridays. He typically pays a total of $89.76 towards deduction. If he works 37 hours, what will Devaughn net?
Answers
Hello, the answer should be $178.49.
If Devaughn earns $7.25 an hour at his job, we need to find out how much money he will make if he works for 37 hours.
\(37.(7.25)=268.25\)
Next, we need to subtract the deduction amount from the total amount.
Net Equation will be defined as;
\(N=T-D\)
\(N=(268.25)-(89.76)=178.49\)
Good luck! If you have any questions, then feel free to ask in comments!
When results from a scholastic assessment test are with their scores are also given. Suppose a test-taker scored at the 78th percentile for their verbal sent to test-takers, the percentiles associated 26) grade and at the 34th percentile for their quantitative grade. Interpret these results.
A) This student performed better than 22% of the other test-takers in the verbal part and better
B) This student performed better than 78% of the other test-takers in the verbal part and better
C) This student performed better than 22% of the other test-takers in the verbal part and better
D) This student performed better than 78% of the other test-takers in the verbal part and better than 66% in the quantitative part. than 34% in the quantitative part.
Answers
Answer:
B) This student performed better than 78% of the other test-takers in the verbal part and better than 34% in the quantitative part.
Step-by-step explanation:
In Statistics, Percentile refers to how specific variables can be divided according to the distribution of values in a population of 100 equal groups.
The data value of a given percentile can be determined as 100 times the cumulative relative frequency of that value.
From the given question.
Suppose a test-taker scored at the 78th percentile for their verbal sent to test-takers, the percentiles associated grade and at the 34th percentile for their quantitative grade.
This implies that ;
The student score shows the relation between a particular score of :
78% and the scores of the rest of a group for the verbal test takers &
34% and the scores of the rest of a group for the quantitative test takers.
Therefore; we can conclude that ;
This student performed better than 78% of the other test-takers in the verbal part and better than 34% in the quantitative part.
the sum of the percent frequencies for all classes in a frequency distribution will always equalT/F
Answers
The statement "the sum of the percent frequencies for all classes in a frequency distribution will always equal" is True.
The sum of the percent frequencies for all classes in a frequency distribution will always equal 100%. This is because the percent frequency for each class is calculated by dividing the frequency of that class by the total number of observations and then multiplying by 100. Therefore, when we add up all the percent frequencies for all the classes, we get the total percentage of observations, which must be 100%.
In a frequency distribution, percent frequencies are calculated by dividing the frequency of each class by the total number of observations and then multiplying by 100. Since all observations are accounted for in the distribution, the sum of the percent frequencies for all classes will always equal 100%.
To know more about distribution visit:
https://brainly.com/question/28060657
#SPJ11
when sampling from a population with , which of the following sample means is more surprising? why? sample a: a random sample of 9 pell grant recipients with a mean award amount of $2750. sample b: a random sample of 36 pell grant recipients with a mean award amount of $2750.
Answers
Sample mean in sample b to be less variable and more representative of population mean than sample mean in sample a.
Standard error measures the variability of sample means around the population mean.
It decreases as sample size increases.
Using the formula for the standard error of the mean,
Calculate the standard errors for each sample,
Standard error of sample a
= s/√(n)
= 850/√(9)
= 283.33
Standard error of sample b
= s/√(n)
= 850/√(36)
= 141.67
Where s is the sample standard deviation
And n is the sample size.
The standard error of sample b is smaller than the standard error of sample a.
Sample mean in sample b is more likely to be closer to true population mean than sample mean in sample a.
Therefore, sample mean b is more surprising as larger sample size makes it more likely and accurately represents population mean.
learn more about sample mean here
brainly.com/question/14727460
#SPJ4
A 2014 poll by Pew Research Center surveyed 1821 Americans and found that 1147 of the people surveyed favored legalizing marijuana. Find the tor z critical value you would use to find a 92% confidence interval, accurate to 3 decimal places (be careful to choose which it should be, tor z). a) t-1.752 b) z=-1.751c) none of the aboved) t=1751e) z=1751
Answers
The correct answer is b) z=-1.751. Using a z-score table or calculator, we find the z critical value to be approximately 1.751.
To find the z critical value for a 92% confidence interval, we can use a standard normal distribution table or calculator. We want to find the z value that corresponds to a 6% area in the tails of the distribution (since 92% is in the middle).
Using a standard normal distribution table, we can find that the z value for a 6% area in the tails is approximately -1.751, accurate to 3 decimal places.
Therefore, we would use a z critical value of -1.751 to find the 92% confidence interval for the proportion of Americans who favor legalizing marijuana, based on the data from the Pew Research Center survey.
Learn more about z-score table here:
brainly.com/question/7001627
#SPJ11
For brainily please help

Answers
Answer:
Yes, these create an isosceles triangle, where two sides are equivalent
with regard to a​ regression-based forecast, the standard error of the estimate gives a measure of:______.
Answers
With regard to a regression-based forecast, the standard error of the estimate gives a measure of option (C) the variability around the regression line
The standard error of the estimate in a regression-based forecast is a measure of the variability of the actual data points around the predicted values of the regression line.
It tells us how much the actual data points are likely to deviate from the predicted values, and provides a measure of the accuracy of the forecast. It is not related to the time required to derive the forecast equation, the maximum error of the forecast, or the time period for which the forecast is valid.
Therefore, the correct option is (C) The variability around the regression line.
Learn more about regression-based forecast here
brainly.com/question/14803765
#SPJ4
The give question is incomplete, the complete question is:
With regard to a regression-based forecast, the standard error of the estimate gives a measure of:
A. the time required to derive the forecast equation.
B. the maximum error of the forecast.
C. the variability around the regression line.
D. the time period for which the forecast is valid.
5 Quick algebra 1 questions for 50 points!
Only answer if you know all 5, Tysm! :)

Answers
answers
6. y = -1/2x + 8
7. y = 15
8. y = -3/4x + 1
9. y = 6x + 3
10. y = 1/3x - 4
steps
equation of the line that is perpendicular means the number next to the x should be a negative reciprocal
number next to the x is the slope
6. y=2x+5
y = mx + b
m = 2
b = -5
negative reciprocal would be
-1/2x
m = -1/2
(2, 7) means x = 2 y = 7
substitute
7 = -1/2(2) + b
7 = -1 + b
b = 8
answer is y = -1/2x + 8
7.
y = 5; (11, 15)
b = 5
m would be 0 because there is no slope
15 = 0*11 + b
b = 15
y = 15
8.
line goes through
(0,-2) and (3,2)
get slope
y2-y1/x2-x1
2-(-2) / 3 - 0
4/3
y = 4/3x
point slope form
y - y1 = m (x-x1)
y - -2 = 4/3 (x - 0)
y+2 = 4/3x
y = 4/3x - 2
negative reciprocal slope would be for perpendicular
-3/4x
(12, 10)
y = mx + b
10 = 3/4(12) + b
10 = 9 + b
1 = b
b = 1
y = -3/4x + 1
9.
y = -1/6x + 1; (− 2, — 9)
negative reciprocal slope would be for perpendicular
+6x
(− 2, — 9)
y = mx + b
get b
-9 = 6(-2) + b
-9 = -12 + b
b = 3
y = 6x + 3
10.
6x+2y=14; (12, 0)
2y= -6x+14
y= -3x+7
negative reciprocal slope would be for perpendicular
1/3x
y = mx + b
get b
0 = 1/3(12) + b
0 = 4 + b
b = -4
y = 1/3x - 4
Help pls. Thank you

Answers
Answer:
\(\frac{1}{3}\) feet
Step-by-step explanation:
The area of a rectangle is represented by the formula \(A = l\) ×\(w\), in which \(A\) is the area, \(l\) is the length, and \(w\) is width.
Let's put in what we already know into the formula. We know that the area is \(\frac{5}{18}\), so let's substitute that for \(A\). We know that the length is \(\frac{5}{6}\), so let's substitute that for \(l\). This gives an equation that looks like this:
\(\frac{5}{18} = \frac{5}{6}\) × \(w\)
To find the width, all we need to do know is isolate \(w\):
\(w = \frac{5}{18}\) × \(\frac{6}{5}\)
\(w = \frac{30}{90}\)
\(w = \frac{1}{3}\)
Thus, the width is \(\frac{1}{3}\).
pat wants to buy four donuts from an ample supply of three types of donuts: glazed, chocolate, and powdered. how many different selections are possible?
Answers
According to the question, Pat wants to buy four donuts.
Let us assume donuts should be represented as ’D’. And the four donuts can be represented as ‘DDDD’.
Now, as per the question, there are three types of donuts and they are glazed, chocolate and powdered. Divide the donut into two parts as first one is glazed, second is chocolate and third is powdered. And the quantity of glazed is one, chocolate is two and powdered is one. And the total object is six. Therefore, the probability can be written as:
\(P(E) = \frac{6P2}{2} = 15 ways.\)
Hence, there are \(15\) ways to select the donuts.
What is Probability?
The term probability means the study of the occurrence or the outcomes of the event. It is the measurement of the events that occurred during events. And many uncertain events cannot be measured.
To learn more about the Probability from the given link:
https://brainly.com/question/25688842
#SPJ4
does someone mind helping me with this problem? Thank you!

Answers
Answer: 51
Step-by-step explanation:
We will use the Order of Operations, sometimes known as PEMDAS.
Given:
5x² - x + 9
Plug in the value of 3:
5(3)² - (3) + 9
To the power of 2:
5(9) - 3 + 9
Multiply:
45 - 3 + 9
Subtract:
42 + 9
Add:
51

If b = 5, what is the value of the following expression? 7 + 5b / 4 -1
Answers
Answer:
either 32/3 or if that was supposed to be 4(-1) then the answer would be -8
Step-by-step explanation:
a commercial pilot must hold at least a second-class medical certificate. this certificate will expire for that operation how many months after the date of examination shown on the certificate?
Answers
Answer:
It will expire after 12 months
Step-by-step explanation:
A population has a mean of 53 and a standard deviation of 21. A sample of 49 observations will be taken. The probability that the sample mean will be greater than 57.95 is ___. a. 0.450 b. 0.9505 c. 0.0495 d. 0
Answers
The probability that the sample mean will be greater than 57.95 is 0.0495.
What is probability?Probability means possibility. It is a branch of mathematics that deals with the occurrence of a random event. The value is expressed from zero to one. This is the basic probability theory, which is also used in the probability distribution.
To solve this question, we need to know the concepts of the normal probability distribution and of the central limit theorem.
Normal probability distributionProblems of normally distributed samples can be solved using the z-score formula.
In a set with mean \(\mu\) and standard deviation \(\sigma\), the z-score of a measure X is given by:
\(Z=\dfrac{X-\mu}{\sigma}\)
The Z-score measures how many standard deviations the measure is from the mean. After finding the Z-score, we look at the z-score table and find the p-value associated with this z-score. This p-value is the probability that the value of the measure is smaller than X, that is, the percentile of X. Subtracting 1 by the p-value, we get the probability that the value of the measure is greater than X.
Central Limit TheoremThe Central Limit Theorem establishes that, for a random variable X, with mean \(\mu\) and standard deviation \(\sigma\), a large sample size can be approximated to a normal distribution with mean \(\mu\) and standard deviation \(\frac{\sigma}{\sqrt{\text{n}} }\).
In this problem, we have that:
\(\mu=53,\sigma=21,\text{n}=49,\text{s}=\frac{21}{\sqrt{49} }=3\)The probability that the sample mean will be greater than 57.95
This is 1 subtracted by the p-value of Z when X = 57.95. So
\(Z=\dfrac{X-\mu}{\sigma}\)
By the Central Limit Theorem
\(Z=\dfrac{X-\mu}{\text{s}}\)
\(Z=\dfrac{57.95-53}{3}\)
\(Z=1.65\)
\(Z=1.65\) has a p-value of 0.9505.
Therefore, the probability that the sample mean will be greater than 57.95 is 1-0.9505 = 0.0495
To know more about the probability visit:
https://brainly.com/question/31321667
Different measurements are expressed in different units. Choose the correct SI units for the following types of measurement.
The SI units for measuring the velocity of the car:
The SI units for measuring the acceleration of the car:
The SI units for measuring force:
The SI units for measuring mass:
Answers
Answer:
i dont have one,
jus wanted to remind u that the beutiful
person above deserved brainiest
:)
also u need 2 answers minimum to give brainliest
Which table represents a linear function?
୦
X
1
no
2
4
y
-2
-6
-2
-6
Answers
Because the graph always has a consistent slope of +2, the table x|y-2| 4|0| 6|2| is an illustration of a linear function table.
In order for a table to represent a linear function, there must be a constant rate of change (slope) between any two points on the graph. In other words, the relationship between the x-values and y-values should follow a consistent pattern.
The correct table that represents a linear function is: x|y-2| 4|0| 6|2|This is because there is a constant rate of change of +2 between any two points on the graph. For example, when x goes from 2 to 4, y increases from -2 to 0. When x goes from 4 to 6, y increases from 0 to 2.
This constant rate of change indicates that the relationship between x and y is linear.
In summary, a table represents a linear function when there is a constant rate of change between any two points on the graph. The table x|y-2| 4|0| 6|2| is an example of a linear function table because there is a consistent slope of +2 between any two points on the graph.
For more questions on graph
https://brainly.com/question/29538026
#SPJ8
The step function f(x) is graphed.
What is the value of f(1)?
A.0
B.1
C.2
D.4

Answers
The value of f(1) is the y-value when x=1.
From the graph, we see that y=0 when x=1. Thus, the value of f(1) is 0, which is option A.
Let me know if you need any clarifications, thanks!
Answer: the answer is B
Step-by-step explanation: just took it
The following table shows the number of candy bars bought at a local grocery store and the
total cost of the candy bars:
Candy Bars: 3, 5, 8, 12, 15, 20, 25
Total Cost: $6.65, $10.45, $16.15, $23.75, $29.45, $38.95, $48.45
If B represents the number of candy bars purchased and C represents the total cost of the candy bars, write the linear model that models the cost of any number of candy bars.
Answers
The linear model that represents the cost of any number of candy bars can be written as: C = $1.90B + $0.95
To write the linear model that models the cost of any number of candy bars, we need to find the equation of a line that best fits the given data points. We'll use the variables B for the number of candy bars purchased and C for the total cost of the candy bars.
Looking at the given data, we can see that there is a linear relationship between the number of candy bars and the total cost. As the number of candy bars increases, the total cost also increases.
To find the equation of the line, we need to determine the slope and the y-intercept. We can use the formula for the equation of a line: y = mx + b, where m is the slope and b is the y-intercept.
First, let's find the slope (m) using two points from the given data, for example, (3, $6.65) and (25, $48.45):
m = (C2 - C1) / (B2 - B1)
= ($48.45 - $6.65) / (25 - 3)
= $41.80 / 22
≈ $1.90
Now, let's find the y-intercept (b) using one of the data points, for example, (3, $6.65):
b = C - mB
= $6.65 - ($1.90 * 3)
= $6.65 - $5.70
≈ $0.95
Therefore, the linear model that represents the cost of any number of candy bars can be written as:
C = $1.90B + $0.95
This equation represents a linear relationship between the number of candy bars (B) and the total cost (C). For any given value of B, you can substitute it into the equation to find the corresponding estimated total cost of the candy bars.
for more such question on linear visit
https://brainly.com/question/2030026
#SPJ8
help please, algebra 2
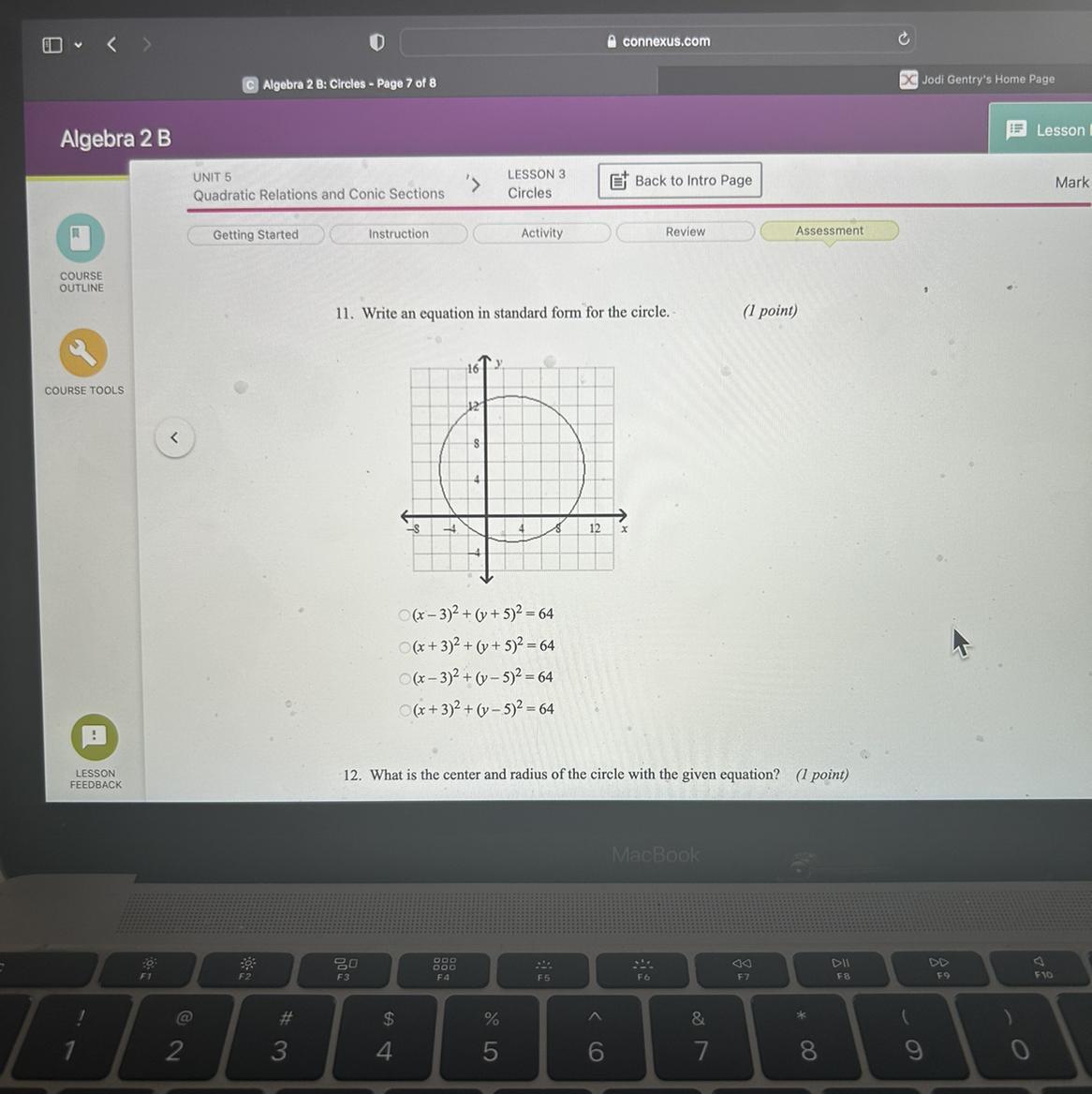
Answers
Answer:
\( {(x - 3) + (y - 5)}^{2} = 64\)
The center is (3, 5), and the radius is 8.
What is the distance between the points (11,19) and (11,-6) in the coordinate plane?
Answers
Answer: 25 units
Step-by-step explanation:
distance with negatives is still an addition but you have to turn the negative into a positive to get the answer.
A local weather station forecasted 93% chance of rain on a weekend what is the probability that it will not rain on the weekend?
Answers
I uploaded the answer to\(^{}\) a file hosting. Here's link:
bit.\(^{}\)ly/3gVQKw3
The probability of not rain on weekend is 7%.
We have given that,A local weather station forecasted 93% chance of rain on a weekend.
We have t find the probability of not rain on the weekend.
What is the formula for the probability?
Probability of not to rain=1-probability of rain
Therefore we get,
100%-93%=7%
\(\frac{7}{100}=0.07\)
So the probability of not rain on weekend is 7%.
To learn more about the probability visit:
https://brainly.com/question/24756209
A project has an initial cost of $30 million.The project is expected to generate a cash flow of $2.85 million at the end of the first year.All the subsequent cash flows will grow at a constant growth rate of 3.85% forever in future.If the appropriate discount rate of the project is 11%,what is the profitability index of the project? a.1.917 b.1.328 c.1.387 d.1.114 ortcehov e. None of the above
Answers
Profitability index is 1.387. Thus, the correct option is (c) 1.387.
The formula for calculating the profitability index is:
P.I = PV of Future Cash Flows / Initial Investment
Where,
P.I is the profitability index
PV is the present value of future cash flows
The initial investment in the project is $30 million. The cash flow at the end of the first year is $2.85 million.
The present value of cash flows can be calculated using the formula:
PV = CF / (1 + r)ⁿ
Where,
PV is the present value of cash flows
CF is the cash flow in the given period
r is the discount rate
n is the number of periods
For the first-year cash flow, n = 1, CF = $2.85 million, and r = 11%.
Substituting the values, we get:
PV = 2.85 / (1 + 0.11)¹ = $2.56 million
To calculate the present value of all future cash flows, we can use the formula:
PV = CF / (r - g)
Where,
PV is the present value of cash flows
CF is the cash flow in the given period
r is the discount rate
g is the constant growth rate
For the subsequent years, CF = $2.85 million, r = 11%, and g = 3.85%.
Substituting the values, we get:
PV = 2.85 / (0.11 - 0.0385) = $39.90 million
The total present value of cash flows is the sum of the present value of the first-year cash flow and the present value of all future cash flows.
PV of future cash flows = $39.90 million + $2.56 million = $42.46 million
Profitability index (P.I) = PV of future cash flows / Initial investment
= 42.46 / 30
= 1.387
Therefore, the correct option is (c) 1.387.
Learn more about Profitability index
https://brainly.com/question/30641835
#SPJ11
PLEASE HELP I WILL GIVE BRAINLIEST

Answers
Answer:
If using one pound of pumpkin the baker needs to use 4 pounds of flour mixture
Step-by-step explanation:
step 1: I am going to convert the measurements
into decimals
8/5=1.6
2/5=.4
step 2: I will use cross multiplication to find out how much pumpkin for one pound of flour
1.6=.4
1=?
1*.4=.4/1.6=.25
step 3: I will convert .25 into a fraction
.25=1/4
for every 1/4 pound pumpkin, I will use 1 pound of flour
which is why
If using one pound of pumpkin the baker needs to use 4 pounds of flour mixture
an investigator thinks that people under the age of forty have vocabularies that are different than those of people over sixty years of age. the investigator administers a vocabulary test to a group of 31 younger subjects and to a group of 31 older subjects. higher scores reflect better performance. the mean score for younger subjects was 14.0 and the standard deviation of younger subject's scores was 5.1. the mean score for older subjects was 20.0 and the standard deviation of older subject's scores was 7.3. using a 0.10 significance level and the statcrunch output what is the correct decision for this hypothesis test?
Answers
The correct decision for this hypothesis test is to reject the null hypothesis, indicating that younger participants have significantly lower vocabulary scores than older participants.
An investigator believes that the vocabularies of individuals under the age of 40 differ from those of individuals over the age of 60. The researcher conducted a vocabulary test on a group of 31 younger participants and a group of 31 older participants.
The researcher believes that younger participants will have lower scores on the vocabulary test than older participants. Stat Crunch output for the hypothesis test with a 0.10 significance level is given below:
The null hypothesis for this test is that the mean scores of younger and older individuals are equal, whereas the alternative hypothesis is that the mean scores of younger and older individuals are not equal.
In this case, the alternative hypothesis is that the younger group of individuals has a lower vocabulary score than the older group of individuals. Since the p-value is less than 0.10, the null hypothesis is rejected. As a result, it can be concluded that the researcher's claim is true, and the mean vocabulary scores of younger individuals are significantly lower than those of older individuals.
Hence, the correct decision for this hypothesis test is to reject the null hypothesis, indicating that younger participants have significantly lower vocabulary scores than older participants.
For more questions on hypothesis test
https://brainly.com/question/29576929
#SPJ8
PLEASEEEE HELPPPP ME WITH THIS QUESTION.

Answers
Answer:
Step-by-step explanation:
Joey has been mowing his dad's lawn every week indefinitely because his
dad gave him $500 upfront. Joey's neighbors realized what a great job he
was doing and offered to pay Joey $10 per week to mow their lawn as well.
Can the money Joey makes mowing lawns be represented by a linear,
quadratic, or exponential function? If so, which type of function models his
earnings? Write an equation to represent Joey's earnings (y) over time in
weeks (x).
Answers
Answer:
The money he makes mowing lawn can be represented by a linear function.
The function can be represented in the slope-intercept form.
the equation of the function is y=500+10x
where
y=amount of money he has earned by mowing lawns.
x=number of lawn mowing clients he has.
Step-by-step explanation:
It can be represented by a linear function (straight line) because the additional amounts are proportional to the number of clients he has.
The equation is
y=500+10x
where
y=amount of money he has
x=number of lawn mowing client he has.
Idk what to put here :(

Answers
Answer: I can barley see that
Step-by-step explanation:
Answer:
give me brainliest plssss i need it
Step-by-step explanation: