How many points of intersection are on the graph of the following system?
lbrace y = x2 + 3x − 7
y − x = 9
The linear-quadratic system has
(select)
points of intersection.
Answers
Answer:
2 points of interception of (3.12 , 12./12) and (-5.12 , 3.87)
Step-by-step explanation:
y − x = 9
y = x + 9
x+9 = x²+3x-7
x²+2x-16=0
x = (-2±√2²-4(1)(-16)) / 2 = (-2 ± √68) / 2 = -1 ± √17
x = 3.12 or x = -5.12
y = 12.12 or y = -3.87
Related Questions
What is the equation of the line with points represented in the table?
A 2-column table with 3 rows. Column 1 is labeled x with entries negative 8, 4, 8. Column 2 is labeled y withentries 6, negative 3, negative 6.
What can you conclude about the line represented in the table? Select all that apply.
Using either slope-intercept or point-slope forms will result in different equations.
Using either slope-intercept or point-slope forms will result in the same equation.
The slope is Negative four-thirds.
The slope is Negative four-thirds.
The y-intercept is 2.
The y-intercept is 0.
Answers
Answer:
b,c,f
Step-by-step explanation:
i did the assignment
Answer:
Step-by-step explanation:

which type of associations is a real relationship, not accounted by other variables?
Answers
A real relationship, not accounted by other variables, is a causal relationship. This type of association suggests that one variable directly causes changes in the other. In other words, there is a cause-and-effect relationship between the two variables.
In this type of association, changes in one variable directly cause changes in the other variable, without any other variables influencing the relationship. This contrasts with spurious or indirect associations, where the relationship between two variables is due to the influence of other variables. To determine if an association is a real relationship, researchers often control for potential confounding variables to isolate the direct effect of the variables in question. However, it is important to note that establishing a causal relationship requires careful research design and data analysis to rule out the effects of other variables that could be influencing the relationship.
To learn more about variables : brainly.com/question/17344045
#SPJ11
sampling refers to a method to select a subset of individuals for the sample from the population so that each has an equal chance of being assigned to the various study conditions. a. random b. snowball c. stratified d. convenience
Answers
Random sampling is the correct answer. Which is option (A).
Sampling refers to a method to select a subset of individuals for the sample from the population so that each has an equal chance of being assigned to the various study conditions is referred to as Random sampling.
What is sampling?
In statistics, sampling is the selection of a subset of individuals from within a statistical population to estimate characteristics of the whole population. Sampling is frequently employed in social science research. The method employed to select a subset of individuals for the sample from the population so that each has an equal chance of being assigned to the various study conditions is known as random sampling.
Content-loaded sampling refers to a form of sampling that is more sophisticated than simple random sampling.
In order to form a sample, it involves first determining which variables (or characteristics) are essential to the study, and then choosing people based on those variables, hence the name "content-loaded."On the other hand, in Stratified sampling, the population is divided into subgroups (strata) based on one or more characteristics that are expected to impact the study's outcomes. The proportion of people chosen from each group should reflect the group's percentage of the overall population.
Snowball sampling is a method for selecting a sample of individuals by locating others who share the characteristics being studied and asking them to suggest additional individuals who might participate in the study. Among the given options, (A) random sampling is the correct answer.
To know more about random sampling: https://brainly.com/question/13219833
#SPJ11
State the limit for the following sequences
2/2 , 2/4 , 2/8 , 2/16 , 2/32
Answers
Answer:
2
,
4
,
8
,
16
,
32
This is a geometric sequence since there is a common ratio between each term. In this case, multiplying the previous term in the sequence by
2
gives the next term. In other words,
a
n
=
a
1
⋅
r
n
−
1
.
Geometric Sequence:
r
=
2
Step-by-step explanation:
i dont need an explanation, answer plz!

Answers
Explanation- 5/3 is 1.67, so multiply 1.67 by 5 and the answer would be equal to 5:3.
a doctor prescribes 3 g of a drug, daily, for a patient. the pharmacist has only 750 mg tablets available. how many tablets will the patient take daily?
Answers
The patient needs to take 4 tablets daily to receive the prescribed dose of 3 grams of the drug.
To determine how many tablets the patient needs to take daily, we need to divide the total amount of the drug prescribed by the dose of each tablet.
Since the patient is prescribed 3 grams of the drug daily, we first need to convert this to milligrams (mg), as the tablets are available in milligram form.
1 gram = 1000 milligrams, so 3 grams = 3,000 milligrams
The pharmacist has 750 mg tablets available, so we can calculate the number of tablets the patient needs to take daily by dividing the prescribed dose by the dose of each tablet:
Number of tablets = Prescribed dose ÷ Dose per tablet
Number of tablets = 3,000 mg ÷ 750 mg
Number of tablets = 4
Therefore, the patient needs to take 4 tablets daily to receive the prescribed dose of 3 grams of the drug.
Therefore, the patient will take 4 tablets daily.
Learn more about medication dosage calculation:https://brainly.com/question/24793154
#SPJ11
How much is 200 tens
Answers
Answer:
if you're sating 200 tens(10), then it equals 2000
Step-by-step explanation:
because you'd multiply them, and 200 times 10 equals 2000.
and if you ment 200 ton, the it's 400000. because a ton is 2000, so 200 times 2000 equals 400000
Please help! Having trouble with this

Answers
STEP BY STEP:
Answer:
B
Step-by-step explanation:
Put them in there calculator
measuring lung function: one of the measurements used to determine the health of a person's lungs is the amount of air a person can exhale under force in one second. this is called the forced expiratory volume in one second, and is abbreviated . assume the mean for -year-old boys is liters and that the population standard deviation is . a random sample of -year-old boys who live in a community with high levels of ozone pollution is found to have a sample mean of liters. can you conclude that the mean in the high-pollution community differs from liters? use the level of significance and the critical value method with the table.
Answers
We can draw the conclusion that there is enough data to demonstrate that, at a significance level of = 0.05, the mean forced expiratory volume in one second for the population of 13-year-old boys in the high-pollution community differs from the established mean of 2.6 liters.
To test whether the mean forced expiratory volume in one second (FEV1) for the population of 13-year-old boys in the high-pollution community differs from the known mean of 2.6 liters, we can use a one-sample t-test.
Given that the sample size is not provided, we assume it to be large enough for the sample mean to follow a normal distribution by the central limit theorem.
The null hypothesis is: H0: μ = 2.6 (the population mean is equal to 2.6 liters)
The alternative hypothesis is: Ha: μ ≠ 2.6 (the population mean is not equal to 2.6 liters)
We will use a significance level of α = 0.05.
To find the critical value, we need to determine the degrees of freedom. Since the sample size is not given, we can assume it to be large enough (say, n > 30) and use a t-distribution with degrees of freedom approximately equal to n - 1.
Using a t-table with 30 degrees of freedom (which is conservative), the critical values for a two-tailed test with α = 0.05 are -2.042 and 2.042.
The test statistic can be calculated as:
t = (sample mean - hypothesized mean) / (sample standard deviation / sqrt(sample size))
t = (sample mean - 2.6) / (population standard deviation / sqrt(sample size))
Since the sample standard deviation is not given, we can use the population standard deviation as an estimate (assuming that the sample is representative of the population). Thus,
t = (3.0 - 2.6) / (0.5 / sqrt(n))
t = 0.4 / (0.5 / sqrt(n))
We do not know the sample size, but we can solve for n using the given sample mean and standard deviation:
standard error = population standard deviation / sqrt(n)
0.5 / sqrt(n) = (3.0 - 2.6) / t
n = (0.5 / ((3.0 - 2.6) / t))^2
n = (0.5 / (0.4 / 2.042))^2
n = 107
Thus, the sample size is 107. Now we can calculate the test statistic:
t = (3.0 - 2.6) / (0.5 / sqrt(107))
t = 4.89
The calculated t-value of 4.89 is greater than the critical value of 2.042, so we reject the null hypothesis.
We can conclude that there is sufficient evidence to suggest that the mean forced expiratory volume in one second for the population of 13-year-old boys in the high-pollution community differs from the known mean of 2.6 liters at a significance level of α = 0.05.
Read more on hypothesis here: brainly.com/question/14913351
#SPJ11
If the figure shown on the grid below is dilated by a scale factor of 2/3 with the center of dilation at (-4,4), what is the coordinate of point M after the dilation?

Answers
After dilation with the given scale factor, the coordinate of M is (-4/3, 2/3)
What is the dilation of a figure?Dilation of a figure is a transformation that changes the size of the figure while preserving its shape. In a dilation, the figure is either enlarged or reduced by a scale factor, which is a constant ratio. The scale factor determines how much the figure is stretched or compressed.
During a dilation, each point of the original figure is multiplied by the scale factor to determine the corresponding position of the dilated figure. The center of dilation is a fixed point around which the figure is expanded or contracted.
In he figure given, the point M have coordinate at (-2, 1)
After dilation with a scale factor of 2/3, the coordinate of M changes to;
M(-2, 1) = 2/3(-2, 1) = -4/3, 2/3
Learn more on dilation of a figure here;
https://brainly.com/question/3457976
#SPJ1
Which of the following prefixes represents the largest value?
Giga
Hector
Kilo
Milli
Answers
the answer is giga
Step-by-step explanation:
cause giga stands fir 1,000,000,000 1 billion
Answer:
giga
Step-by-step explanation:
If the length of a rectangle is increased by 40% and the width is decreased by 40% then the area:.
Answers
The Area of Rectangle would be Decreased by 16% of the original Area. Now the Area of Rectangle is 84%.
Let the Length of rectangle be ‘x’
And width of rectangle be ‘y’
Area of Rectangle = Length X Width
Original Area of rectangle = x X y = xy square units
As the length is increased by 40% then, the new length would be 1+40% i.e 1.4 and,
The width is decreased by 40% then, the new width would be 1-40% i.e 0.6
New Length = 1.4x
New Width = 0.6y
Now , New Area of Rectangle = 1.4x X 0.6y
= 0.84xy square units
The effect is that the New Area of the rectangle is 84% of the original area. There is a decrease of 16% in the area.
To know more about Rectangle, Click here :
https://brainly.com/question/27924963
#SPJ4
Please help, I'm stuck and really need this.

Answers
Answer:
r = 8
Step-by-step explanation:
To find the radius with only the area you do r = \(\sqrt{A/\pi }\)
Since your area 64\(\pi\) = 201.0619298 then 201.0619298/\(\pi\) = 64
\(\sqrt{64}\) = 8
Hope this helps!!
The make African elephant at the city zoo has a mass of 5450 kg. What is its mass in scientific notation
Answers
The mass in scientific notation is \(5.45 * 10^3 kg\), this means that the mass of the African elephant is 5.45 multiplied by 1000,
To write the mass of the African elephant in scientific notation, we need to express it as a number between 1 and 10, multiplied by a power of 10. To do this, we can start by moving the decimal point in 5450 kg to the left until we have a number between 1 and 10. This gives us 5.45 kg.
Next, we need to determine the power of 10 that we multiplied by to get this number. To do this, we count the number of places we moved the decimal point, which is three places to the left. Therefore, the mass of the African elephant in scientific notation is:
\(5.45 * 10^3 kg\)
This means that the mass of the African elephant is 5.45 multiplied by 1000, which is the same as 5450 kg in standard notation. Writing the mass in scientific notation makes it easier to work with very large or small numbers, as it simplifies the representation of the number and makes it more manageable.
Learn more about decimal :
https://brainly.com/question/30958821
#SPJ4
Which function g(x) shows the parent function vertically stretched by a factor of 3, reflected over the x-axis. and translated right 2 units and translated up 4 units.
A
g(x)=−13∣x−2∣+4g(x)=-\frac{1}{3}\left| x-2\right| +4g(x)=−
3
1
∣x−2∣+4
B
g(x)=13∣x−2∣+4g(x)=\frac{1}{3}\left| x-2\right| +4g(x)=
3
1
∣x−2∣+4
C
g(x)=3∣x−2∣+4g(x)=3\left| x-2\right| +4\newlineg(x)=3∣x−2∣+4
D
g(x)=−3∣x−2∣+4g(x)=-3\left| x-2\right| +4\newlineg(x)=−3∣x−2∣+4
Answers
The function that represents the parent function vertically stretched by a factor of 3, reflected over the x-axis, and translated right 2 units and up 4 units is g(x) = 3∣x - 2∣ + 4.
This can be explained as follows:
In the parent function ∣x∣, the absolute value of x ensures that the graph is reflected over the x-axis, resulting in a V-shaped graph in the positive y-axis region. By replacing x with (x - 2), we achieve a horizontal translation of 2 units to the right. Next, multiplying the absolute value term by 3 vertically stretches the graph by a factor of 3, making the V-shape narrower and taller. Finally, adding 4 to the function translates the graph upward by 4 units.
Thus, the function g(x) = 3∣x - 2∣ + 4 combines the vertical stretching, reflection, and translations described above to match the given criteria.
Learn more about function here: brainly.com/question/30721594
#SPJ11
There are 15 yellow marbles in a jar. Yellow is the only color of marbles in the jar. You take out one yellow marble and do not replace it. Then you pick a 2nd yellow marble. In this case, how do you calculate the probability of picking 2 yellow marbles separately?
Answers
Answer:
what does the color of the marble matter for?
Step-by-step explanation:
i am just wondering sorry
brainliest,
2 less than a number d

Answers
Answer:
d - 2
Step-by-step explanation:
saying it out loud helps :)
please can you guy help for this questiong
please

Answers
Answer:
Step-by-step explanation:
From the figure attached,
Given: ∠P ≅ ∠S
TQ ≅ RQ
To Prove : ΔQRS ≅ ΔQTP
Statements Reasons
1). ∠P ≅ ∠S, TQ ≅ RQ Given
2). ∠RQS ≅ ∠TQP Reflexive property
3). ΔQRS ≅ ΔQTP AAS
Find the equation of the line
Y= __x + __

Answers
Answer:
Step-by-step explanation:
(0, -9) and (3,3)
(3+9)/(3-0) = 12/3 = 4
y + 9 = 4(x - 0)
y + 9 = 4x - 0
y = 4x - 9
A bus arrives every 10 minutes at a bus stop. It is assumed that the waiting time for a particular individual is a random variable with a continuous uniform distribution.
a) What is the probability that the individual waits more than 7 minutes?
b) What is the probability that the individual waits between 2 and 7 minutes?A continuous random variable X distributed uniformly over the interval (a,b) has the following probability density function (PDF):fX(x)=1/0.The cumulative distribution function (CDF) of X is given by:FX(x)=P(X≤x)=00.
Answers
In the following question, among the various parts to solve- a) the probability that the individual waits more than 7 minutes is 0.3. b)the probability that the individual waits between 2 and 7 minutes is 0.5.
a) The probability that an individual will wait more than 7 minutes can be found as follows:
Given that the waiting time of an individual is a continuous uniform distribution and that a bus arrives at the bus stop every 10 minutes.Since the waiting time is a continuous uniform distribution, the probability density function (PDF) can be given as:fX(x) = 1/(b-a)where a = 0 and b = 10.
Hence the PDF of the waiting time can be given as:fX(x) = 1/10The probability that an individual waits more than 7 minutes can be obtained using the complementary probability. This is given by:P(X > 7) = 1 - P(X ≤ 7)The probability that X ≤ 7 can be obtained using the cumulative distribution function (CDF), which is given as:FX(x) = P(X ≤ x) = ∫fX(t) dtwhere x ∈ [a,b].In this case, the CDF of the waiting time is given as:FX(x) = ∫0x fX(t) dt= ∫07 1/10 dt + ∫710 1/10 dt= [t/10]7 + [t/10]10= 7/10Using this, the probability that an individual waits more than 7 minutes is:P(X > 7) = 1 - P(X ≤ 7)= 1 - 7/10= 3/10= 0.3So, the probability that the individual waits more than 7 minutes is 0.3.
b) The probability that the individual waits between 2 and 7 minutes can be calculated as follows:P(2 < X < 7) = P(X < 7) - P(X < 2)Since the waiting time is a continuous uniform distribution, the PDF can be given as:fX(x) = 1/10Using the CDF of X, we can obtain:P(X < 7) = FX(7) = (7 - 0)/10 = 0.7P(X < 2) = FX(2) = (2 - 0)/10 = 0.2Therefore, P(2 < X < 7) = 0.7 - 0.2 = 0.5So, the probability that the individual waits between 2 and 7 minutes is 0.5.
For more such questions on probability
https://brainly.com/question/24756209
#SPJ11
I’ll mark brainly help hurry

Answers
The median height of the boys aged 13 years is 160 cm.
option D.
What is the median height of the boys?From the given equation of line of best fit, the median height of the boys aged 13 years is calculated as follows;
The given equation for line of best fit is;
y = 6.5x + 75.5
where;
x is the number of yearsy is the median height is cm.when x = 13 years, the value of y, median height, is calculated as follows;
y = 6.5 (13) + 75.5
y = 160 cm
Thus, the median height of the boys aged 13 years is determined by applying the given equation for line of best fit,
Learn more about median height here: https://brainly.com/question/31221740
#SPJ1
a researcher wishes to determine whether the salaries of professional nurses employed by private hospitals are higher than those of nurses employed by government-owned hospitals. she selects a random sample of nurses from each type of hospital and calculates the means and standard deviations of their salaries. private hospital nurses had a mean salary of $26,800 (sample of 100 nurses), while the government-owned hospital nurses had a mean salary of $25,400 (sample of 800). at the 0.01 level, can she conclude that the private hospitals pay more than the government hospitals? it is known that salaries vary normally and and it is reasonable to assume there is no difference in variability of salary between the two groups.
Answers
the researcher can conclude that private hospitals pay more than government-owned hospitals based on the sample data.
To test whether private hospitals pay more than government-owned hospitals, we can use a two-sample t-test with equal variances.
The null hypothesis is that there is no difference in mean salary between the two groups:
H0: μprivate = μgovernment
The alternative hypothesis is that private hospitals pay more than government-owned hospitals:
Ha: μprivate > μgovernment
We can use a significance level of 0.01, which corresponds to a critical value of t = 2.364 (with degrees of freedom = 898).
First, we need to calculate the pooled standard deviation:
Sp = sqrt(((n private - 1)s^2private + (n government - 1)s^2government) / (n private + n government - 2))
where n private and n government are the sample sizes, s^2private and s^2government are the sample variances, and s^2pooled is the pooled variance.
Plugging in the values, we get:
Sp = sqrt(((100-1) * 186^2 + (800-1) * 176^2) / (100 + 800 - 2)) = 176.43
Next, we calculate the test statistic:
t = (x(bar)private - x(bar)government) / (Sp * sqrt(1/n private + 1/n government))
where x(bar)private and x(bar)government are the sample means.
Plugging in the values, we get:
t = (26,800 - 25,400) / (176.43 * sqrt(1/100 + 1/800)) = 3.14
Since our test statistic (3.14) is greater than the critical value (2.364), we reject the null hypothesis and conclude that private hospitals pay more than government-owned hospitals at a significance level of 0.01.
To learn more about sample visit:
brainly.com/question/13287171
#SPJ11
A factory makes Jars in batches of 160 and lids in batches of 216. The next puts the jars in a row, fills them and then attaches the lid. They want to make the largest row possible so the jars and lids are divided evenly by the rows. What is the largest row possible?
Answers
Answer:
8 is the largest row possible
Step-by-step explanation:
What this question is simply asking is to find the greatest common factor of 216 and 160
The greatest common factor of 216 and 160 is 8
So what this mean is that the largest row possible is 8
2) Based on the results in the table, what is the probability of the spinner
landing on orange? (as a decimal to the nearest hundredth)
A) 0.20
B) 0.22
C) 0.24
D) 0.26

Answers
The value of the probability of orange is (c) 0.24
How to evaluate the probabilityFrom the question, we have the following parameters that can be used in our computation:
Spinner and the number of spins
Using the above as a guide, we have the following:
Orange = 12
Total = 50
So, we have
P(Orange) = Orange/Total
Substitute the known values in the above equation, so, we have the following representation
P(Orange) = 12/50
Evaluate
P(Orange) = 0.24
Read more about probability at
brainly.com/question/251701
#SPJ1
The total measure of the angles is (n−2)·180°, where n=8. The term regular means all interior angle measures are the same. How can you determine each angle measure from the total angle measure?
Answers
Each measure of the angle when the total measure of the angles is (n−2)·180° and n is 8 will be 235°.
How to calculate the angle?From the information, the total measure of the angles is (n−2)·180°, where n=8. The term regular means all interior angle measures are the same.
It should be noted that in Mathematics, the value of the sum of angles is Illustrated in this case. We can determine each angle measure from the total angle measure thus:
(n - 2) × 180
n = 8
It should be noted that n in this case simply means the number of sides
= (n - 2) × 180
= (8 - 2) × 180
= 1080°
Each measure of the angle will be:
= 1080° / 8
= 135°
Learn more about angles on:
brainly.com/question/25716982
#SPJ1
A pharmaceutical company wants to test the effectiveness of a new allergy drug. The company identifies 250 females 30-35 years old who suffer from severe allergies. The subjects are randomly assigned into two groups. One group is given the new allergy drug and the other is given a placebo that looks exactly like the new allergy drug. After six months, the subjects' symptoms are studied and compared. Answer parts (a) through (c) below.
Answers
After six months, the subjects' symptoms are studied and compared. Answer parts are given below.
What is the hypothesis?An assumption or concept is given as a hypothesis for the purpose of debating it and testing if it might be true.
Given:
A pharmaceutical company wants to test the effectiveness of a new allergy drug.
The company identifies 250 females 30–35 years old who suffer from severe allergies.
The subjects are randomly assigned into two groups.
One group is given the new allergy drug and the other is given a placebo that looks exactly like the new allergy drug.
After six months, the subjects' symptoms are studied and compared.
Here, 30-35 year-old girls are used to test the new allergy medication's effects.
(a)
Females between the ages of 30 and 35 who are the test subjects are the experimental units.
The new allergy medication, whose results are being studied, is the remedy.
It's best to choose C.
(b)
A bias may develop if a researcher or patient knows whether subjects received a medication or a placebo.
In this case, choice B is preferable.
(c)
If neither the researcher nor the subject knew whether they were receiving a medicine or a placebo, the study would be considered double-blind.
In this case, choice A is preferable.
Therefore, all the correct choices are given above.
To learn more about the hypothesis;
brainly.com/question/29519577
#SPJ1
The complete question is given in the image.

The base angles of a trapezoid are two _____ angles of a trapezoid whose common side is the base.
Answers
Answer:
Consecutive
Step-by-step explanation:
Answer:
consecutive
Step-by-step explanation:
have a good day!
The displacement (in centimeters) of a particle moving back and forth along a straight line is given by the equation of motion s = 5 sin πt + 2 cos πt, where t is measured in seconds. (Round your answers to two decimal places.)
Required:
a. Find the average velocity during each time period.
b. Estimate the instantaneous velocity of the particle when t = 1
Answers
According to the question For ( a ) The average velocity during this time
period is \(\[\text{Average velocity} = \frac{\Delta s}{\Delta t} = \frac{-4}{1} = -4 \, \text{cm/s}\]\). For ( b ) The estimated
instantaneous velocity of the particle when \(\( t = 1 \) is \( -5\pi \) cm/s.\)
a. Average velocity during each time period:
The equation of motion for the displacement of the particle is given by:
\(\[ s = 5\sin(\pi t) + 2\cos(\pi t) \]\)
To find the average velocity, we need to calculate the change in displacement divided by the change in time.
For the time period \(\( t = 0 \)\) to \(\( t = 2 \)\) :
\(\[\Delta t = 2 - 0 = 2\]\)
\(\[\Delta s = s(2) - s(0) = (5\sin(\pi(2)) + 2\cos(\pi(2))) - (5\sin(\pi(0)) + 2\cos(\pi(0)))\]\)
Using the values of \(\( \sin(2\pi) = 0 \)\) and \(\( \cos(2\pi) = 1 \)\), we can simplify the equation:
\(\[\Delta s = (5\sin(\pi(2))) + 2(1) - (5\sin(\pi(0)) + 2\cos(\pi(0))) = 0 + 2 - (0 + 2) = 2 - 2 = 0\]\)
The average velocity during this time period is:
\(\[\text{Average velocity} = \frac{\Delta s}{\Delta t} = \frac{0}{2} = 0 \, \text{cm/s}\]\)
For the time period \(\( t = 2 \)\) to \(\( t = 3 \)\) :
\(\[\Delta t = 3 - 2 = 1\]\)
\(\[\Delta s = s(3) - s(2) = (5\sin(\pi(3)) + 2\cos(\pi(3))) - (5\sin(\pi(2)) + 2\cos(\pi(2)))\]\)
Using the values of \(\( \sin(3\pi) = 0 \)\) and \(\( \cos(3\pi) = -1 \)\) , we can simplify the equation:
\(\[\Delta s = (5\sin(\pi(3))) + 2(-1) - (5\sin(\pi(2)) + 2\cos(\pi(2))) = 0 - 2 - (0 + 2) = -4\]\)
The average velocity during this time period is:
\(\[\text{Average velocity} = \frac{\Delta s}{\Delta t} = \frac{-4}{1} = -4 \, \text{cm/s}\]\)
b. To estimate the instantaneous velocity of the particle when \(\( t = 1 \)\) , we can use the velocity equation we obtained earlier:
\(\[v = 5\pi\cos(\pi t) - 2\pi\sin(\pi t)\]\)
Plugging in \(\( t = 1 \)\) :
\(\[v(1) = 5\pi\cos(\pi(1)) - 2\pi\sin(\pi(1))\]\)
Using the values of \(\( \sin(\pi) = 0 \) and \( \cos(\pi) = -1 \)\) , we can simplify the equation:
\(\[v(1) = 5\pi(-1) - 2\pi(0) = -5\pi\]\)
The estimated instantaneous velocity of the particle when \(\( t = 1 \) is \( -5\pi \) cm/s.\)
To know more about instantaneous visit-
brainly.com/question/16944977
#SPJ11
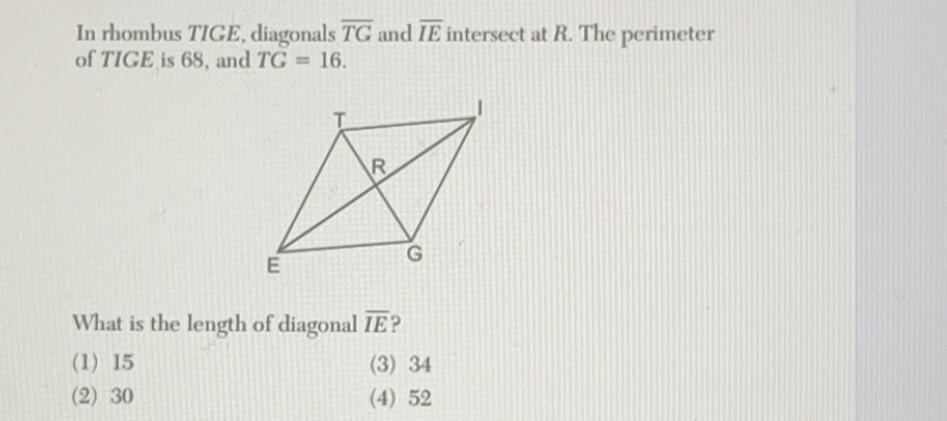
7.
in rhombus tige, diagonals tg and ie intersect at r. the perimeter
of tige is 68, and tg 16.
Answers
In the given diagram, the length of diagonal IE is 30. The correct option is (2) 30
Calculating the length of a diagonal of a RhombusFrom the question, we are to determine the length of diagonal IE
From the given information,
/TG/ = 16
∴ /RG/ = 16÷2 = 8
NOTE: The diagonals of a rhombus bisect each other at right angles
Then,
/GE/² = /ER/² + /RG/² (Pythagoras' theorem)
From the given information, the perimeter of the rhombus is 68
Since all the sides of a rhombus are equal to one another,
Then,
/GE/ = 68÷4
/GE/ = 17
Thus,
17² = /ER/² + 8²
289 = /ER/² + 64
/ER/² = 289 - 64
/ER/² = 225
/ER/ = √225
/ER/ = 15
But,
/IE/ = 2 × /ER/
∴ /IE/ = 30
Hence, the length of diagonal IE is 30. The correct option is (2) 30
Learn more on Calculating length of a diagonal of a rhombus here: https://brainly.com/question/12354523
#SPJ1
Answer:j un ih i9
Step-by-step explanation:
b un ih 9
Use the below information for questions 2a - 2b:
State Probability Return on A Return on B Return on C
Boom 0.30 0.35 0.25 0.10
Average 0.50 0.20 0.15 0.25
Bust 0.20 0.05 0.10 0.35
2a. Find the Mean and Variance of Asset A
2b. Find the Correlation coefficient of A and C
Answers
Answer to 2a: The mean of Asset A is 0.235 and the variance is 0.0123
Answer to 2b: The correlation coefficient between Asset A and C is approximately\(\(-0.670\) (Boom), \(-0.187\) (Average), \(-0.670\)\)(Bust).
2a. Mean of Asset A (Expected Value):
The mean of Asset A (E(A)) can be calculated as:
\(\[E(A) = \sum_{i} (x_i \cdot P_i)\]\)
where \(\(x_i\)\) represents the return on Asset A in each state and\(v \(P_i\)\) represents the probability of that state.
Using the given information, we have:
Boom:
\(\(E(A) = (0.35 \cdot 0.30) + (0.20 \cdot 0.50) + (0.05 \cdot 0.20) = 0.235\)\)
Average:
\(\(E(A) = (0.35 \cdot 0.30) + (0.20 \cdot 0.50) + (0.05 \cdot 0.20) = 0.235\)\)
Bust:
\(\(E(A) = (0.35 \cdot 0.30) + (0.20 \cdot 0.50) + (0.05 \cdot 0.20) = 0.235\)\)
Therefore, the mean of Asset A is\(\(E(A) = 0.235\).\)
2b. Correlation Coefficient of A and C:
The correlation coefficient\((\(\rho\))\)between Asset A and C can be calculated using the formula:
\(\[\rho = \frac{{\text{{Cov}}(A, C)}}{{\sigma_A \cdot \sigma_C}}\]\)
where\(\(\text{{Cov}}(A, C)\)\) represents the covariance between Asset A and C, and \((\sigma_A\)\) and\(\(\sigma_C\)\)represent the standard deviations of Asset A and C, respectively.
Using the given information, we have:
Boom:
\(\(\text{{Cov}}(A, C) = (0.35 - 0.235) \cdot (0.10 - 0.25) = -0.017\)\)
Average:
\(\(\text{{Cov}}(A, C) = (0.20 - 0.235) \cdot (0.15 - 0.25) = -0.005\)\)
Bust:
\(\(\text{{Cov}}(A, C) = (0.05 - 0.235) \cdot (0.35 - 0.25) = -0.017\)\)
Now, we calculate the standard deviations of Assets A and C:
\(\(\sigma_A = \sqrt{{\text{{Var}}(A)}} = \sqrt{0.0123} \approx 0.1108\)\)
\(\(\sigma_C = \sqrt{{\text{{Var}}(C)}} = \sqrt{0.0517} \approx 0.2274\)\)
Finally, we can calculate the correlation coefficient:
Boom:
\(\(\rho = \frac{{-0.017}}{{0.1108 \cdot 0.2274}} \approx -0.670\)\)
Average:
\(\(\rho = \frac{{-0.005}}{{0.1108 \cdot 0.2274}} \approx -0.187\)\)
Bust:
\(\(\rho = \frac{{-0.017}}{{0.1108 \cdot 0.2274}} \approx -0.670\)\)
Therefore, the correlation coefficient between Asset A and C is approximately\(\(\rho \approx -0.670\) (Boom), \(\rho \approx -0.187\) (Average), and \(\rho \approx -0.670\) (Bust).\)
Answer to 2a: \(The mean of Asset A is \(0.235\) and the variance is \(0.0123\.\)
Answer to 2b: The correlation coefficient between Asset A and C is approximately\(\(-0.670\) (Boom), \(-0.187\) (Average), \(-0.670\)\)(Bust).
Learn more Mean and Variance
https://brainly.com/question/31485382
#SPJ11