Laura is currently paying off her four-year car financing. when she purchased her car, it had a list price of $19,858. laura traded in her previous car, a good-condition 2000 honda insight, for 85% of the trade-in value listed below, financing the rest of the cost at 9.5% interest, compounded monthly. she also had to pay 9.27% sales tax, a $988 vehicle registration fee, and a $77 documentation fee. however, because laura wants to pay off her loan more quickly, she makes a total payment of $550 every month. how much extra is she paying monthly? round all dollar values to the nearest cent.
Answers
Laura is paying each month:
extra payment = $550 - monthly payment
To calculate how much extra Laura is paying each month, we first need to calculate the total cost of her car financing. Here are the steps:
Calculate the trade-in value of Laura's old car. We don't have the exact value, but we know that she received 85% of the trade-in value listed below, so we can set up an equation:
0.85 * trade-in value = value Laura received
Solving for the trade-in value, we get:
trade-in value = value Laura received / 0.85
Add the trade-in value to the list price of the new car to get the total cost before taxes and fees:
total cost before taxes and fees = $19,858 + trade-in value
Add the sales tax, registration fee, and documentation fee to get the total cost of the car financing:
total cost = (1 + 0.0927) * total cost before taxes and fees + $988 + $77
Calculate the monthly payment using the formula for a loan with monthly compounding:
monthly payment = (principal * monthly interest rate) / (1 - (1 + monthly interest rate)^(-number of months))
We know that Laura is financing the rest of the cost after her trade-in value, so:
principal = total cost - value Laura received
monthly interest rate = 0.095 / 12
number of months = 48 (since it's a four-year financing)
Substituting these values into the formula, we get:
monthly payment = ($19,858 + trade-in value - value Laura received) * 0.007916 / \((1 - (1 + 0.007916)^{(-48)})\)
Now that we have the total monthly payment, we can calculate how much extra Laura is paying each month:
extra payment = $550 - monthly payment
Note that this assumes that Laura doesn't have any other fees or interest charges on her car financing, such as late payment fees or penalties for paying off the loan early. If there are any additional fees or charges, the calculation may be different.
To know more about extra payment, refer to the link below:
https://brainly.com/question/30856122#
#SPJ11
Related Questions
What is the name of the segment inside the large triangle?
1. Perpendicular bisector
2.Midsegment
3.Angle Bisector
4.Median

Answers
The name of the segment inside the large triangle is called the: 3. angle bisector.
What is an Angle Bisector?The word "bisect" means to divide into two equal halves. Therefore, an angle bisector can be defined as a line segment that divides the an angle in a triangle into two parts that are of the same angle measure.
The image shows a triangle which has a segment that divides a vertex angle into equal parts. Thus, the segment can be named as an angle bisector.
A perpendicular bisector divides a segment into two equal halves at right angle, while a midsegment joins the middle points of two sides of a triangle. The median also, is a segment that joins a vertex of a triangle to the midpoint of the side that is opposite the angle.
Therefore, we can state that the name of the segment is: 3. angle bisector.
Learn more about the angle bisector on:
https://brainly.com/question/24334771
#SPJ1
At the end of 1st Quarter of 2009 the median price of a single-family home in Charleston/No. Charleston was $184,990. Single-family home prices in Charleston/No. Charleston decreased from the 1st Qtr of 2008 by 8.15%. NOTE: Depreciation means a negative value for r. (a). Estimate the median price of a single-family home in the 1st Qtr of 2008.
(b). If the median price of a single-family home falls at the same rate for the next 2 years, estimate the median price of a single-family home in the 1st Qtr of 2011.
Answers
The estimated median price of a single-family home in Charleston/No. Charleston in the 1st Quarter of 2008 is $201,048. If the median price continues to decrease at the same rate for the next two years, the estimated median price of a single-family home in the 1st Quarter of 2011 would be $144,458.
(a) To estimate the median price of a single-family home in the 1st Quarter of 2008, we need to calculate the original price before the 8.15% decrease. Let's assume the original price was P. The price after the decrease can be calculated as P - 8.15% of P, which translates to P - (0.0815 * P) = P(1 - 0.0815). Given that the end of 1st Quarter of 2009 median price was $184,990, we can set up the equation as $184,990 = P(1 - 0.0815) and solve for P. This gives us P ≈ $201,048 as the estimated median price of a single-family home in the 1st Quarter of 2008.
(b) If the median price of a single-family home falls at the same rate for the next two years, we can calculate the price for the 1st Quarter of 2011 using the estimated median price from the 1st Quarter of 2009. Starting with the median price of $184,990, we need to apply an 8.15% decrease for two consecutive years. After the first year, the price would be $184,990 - (0.0815 * $184,990) = $169,805.95. Applying the same percentage decrease for the second year, the price would be $169,805.95 - (0.0815 * $169,805.95) = $156,012.32. Therefore, the estimated median price of a single-family home in the 1st Quarter of 2011 would be approximately $144,458.
To learn more about median click here: brainly.com/question/300591
#SPJ11
How many people surveyed in New York wear Nike's.
In San Francisco 165 people wear Nike's 80 people wear Adidas
In New York 116 people wear Nike's 148 wear Adidas
Answers
Answer:
116
Step-by-step explanation:
it says in the description that 116 people in new york wear nike's
Charlie’s Wholesale Fruit Company, located in McAllen, Texas, is considering the purchase of a new fleet of trucks to be used in the delivery of fruits and vegetables grown in the Rio Grande Valley of Texas. If the company goes through with the purchase, it will spend $350,000 on eight rigs and $50,000 on the shipping cost. The new trucks will be kept for five years, during which time they will be depreciated toward a $40,000 salvage value using straight-line depreciation. The rigs are expected to have a market value in five years equal to $30,000. The new trucks will be used to replace the company’s older fleet of eight trucks, which are fully depreciated without any salvage value but can be sold for an estimated $20,000 today. The existing truck fleet is expected to be usable for five more years, after which time the rigs will have market value of $1,000. The existing fleet of trucks uses $250,000 per year in diesel fuel, whereas the new, more efficient fleet will use only $150,000. In addition, the new fleet will be covered under warranty, so the maintenance cost per year are expected to be only $10,000 compared to $35,000 for the existing fleet. Those changes in operating activities will have decrease the company’s requirement on net operating working capital as much as $20,000. The company’s current revenue is $800,000 and projected to grow at 10% per annum for the next five years. Cost of goods sold is always 50% of the company’s revenue. A $50,000 annual fixed operating expense (excluding fleet related costs) will remain the same for the next five years. The company has none fixed assets except for the fleet. The company faces a marginal tax rate of 30%. a. Calculate the replacement free cash flows generated by this proposed project! b. Calculate the Payback Period of this proposed project! c. If Charlie requires a 15% discount rate for the new investments, calculate the NPV and Profitability Index of this proposed project! d. Calculate the IRR of this proposed project! e. Based on your answer on b, c, and d, should the fleet be replaced? Why?
Answers
a. The replacement free cash flows is $255,000
b. The Payback Period time required to recover the initial investment is 2.7778 years.
d. By calculating the NPV at various discount rates, we can determine the rate at which NPV is closest to zero.
a. To calculate the replacement free cash flows, we need to consider the cash flows associated with the new fleet of trucks. Here's the calculation:
Initial cash outflow: Purchase cost of new trucks + Shipping cost
= $350,000 + $50,000
= $400,000
Annual cash flows:
Operating cost savings:
Diesel fuel savings: $250,000 - $150,000 = $100,000
Maintenance cost savings: $35,000 - $10,000 = $25,000
Net operating working capital reduction: $20,000
Total operating cost savings per year: $100,000 + $25,000 + $20,000 = $145,000
Revenue increase:
Revenue growth rate: 10%
Year 1 revenue increase: $800,000 * 10% = $80,000
Year 2 revenue increase: $800,000 * 10% = $80,000
Year 3 revenue increase: $800,000 * 10% = $80,000
Year 4 revenue increase: $800,000 * 10% = $80,000
Year 5 revenue increase: $800,000 * 10% = $80,000
Salvage value: Market value of the new trucks at the end of 5 years = $30,000
Free cash flows:
Year 0: Initial cash outflow = -$400,000
Year 1: Cash flow = Operating cost savings + Revenue increase = $145,000 + $80,000 = $225,000
Year 2: Cash flow = Operating cost savings + Revenue increase = $145,000 + $80,000 = $225,000
Year 3: Cash flow = Operating cost savings + Revenue increase = $145,000 + $80,000 = $225,000
Year 4: Cash flow = Operating cost savings + Revenue increase = $145,000 + $80,000 = $225,000
Year 5: Cash flow = Operating cost savings + Revenue increase + Salvage value = $145,000 + $80,000 + $30,000 = $255,000
b. The Payback Period is the time required to recover the initial investment. To calculate it, we sum the cash flows until they equal or exceed the initial investment. Here's the calculation:
Payback Period = Number of years to recover initial investment
= 2 years (Year 1 cash flow + Year 2 cash flow)
+ (Remaining investment / Year 3 cash flow)
= 2 years + ($400,000 - $225,000) / $225,000
= 2 years + 0.7778 years
= 2.7778 years
c. To calculate the Net Present Value (NPV) and Profitability Index (PI), we need to discount the cash flows using the given discount rate of 15%. Here's the calculation:
Discount rate: 15%
Present value factor for each year:
Year 0: 1 / (1 + Discount rate)^0 = 1
Year 1: 1 / (1 + Discount rate)^1 = 0.8696
Year 2: 1 / (1 + Discount rate)^2 = 0.7561
Year 3: 1 / (1 + Discount rate)^3 = 0.6575
Year 4: 1 / (1 + Discount rate)^4 = 0.5718
Year 5: 1 / (1 + Discount rate)^5 = 0.4972
NPV calculation:
NPV = (Year 0 cash flow) + (Year 1 cash flow * Present value factor) + (Year 2 cash flow * Present value factor) + ...
= -$400,000 + ($225,000 * 0.8696) + ($225,000 * 0.7561) + ($225,000 * 0.6575) + ($225,000 * 0.5718) + ($255,000 * 0.4972)
Profitability Index calculation:
PI = NPV / Initial investment
= NPV / $400,000
d. To calculate the Internal Rate of Return (IRR), we find the discount rate that makes the NPV equal to zero. Here's the calculation:
IRR = Discount rate that makes NPV equal to zero
By calculating the NPV at various discount rates, we can determine the rate at which NPV is closest to zero.
e. Based on the information provided, we can determine if the fleet should be replaced by considering the Payback Period, NPV, Profitability Index, and IRR.
If the Payback Period is within the company's acceptable timeframe and the NPV is positive, or the Profitability Index is greater than 1, and the IRR exceeds the company's required rate of return, then replacing the fleet would be financially favorable. If any of these criteria are not met, it would indicate that the replacement may not be the best option.
Please note that the calculation of IRR requires further information, and the final decision should consider additional factors such as qualitative aspects, operational requirements, and strategic considerations.
Without the specific values for cash flows in each year, it is not possible to provide a definitive answer to whether the fleet should be replaced based on the given information.
To learn more about Profitability Index
https://brainly.com/question/30924864
#SPJ11
Determine the simple interest earned on a $6000 investment at 5.5% for 12 years
Answers
Answer:
369,000
Step-by-step explanation:
$6000x5.5x12
Which of the following is an example of a data set with 5 values for which the standard deviation is zero. a) -2.-1.0.1.2 b) 4.4.4.4.4 c) -5,-3.0.3.5 d) 1,2,3,4,5
Answers
The standard deviation for the dataset (4, 4, 4, 4, 4) is zero (0)
To find a data set with 5 values for which the standard deviation is zero,
⇒ (4, 4, 4, 4, 4)
For the above dataset;
Mean μ = 4
Number of samples n = 5
Standard deviation σ = \(\sqrt{\frac{sumof(xi - x)^2}{n} }\)
= \(\sqrt{\frac{(4-4)^2+(4-4)^2+(4-4)^2+(4-4)^2+(4-4)^2}{5} }\)
= 0
Therefore, for the dataset (4, 4, 4, 4, 4) the standard deviation is zero(0).
To learn more about standard deviation click here:
brainly.com/question/14747159
#SPJ4
A function h(x) is defined by the equation h(x) = sqrt x-2 + 3. Which is the graph of h(x)?

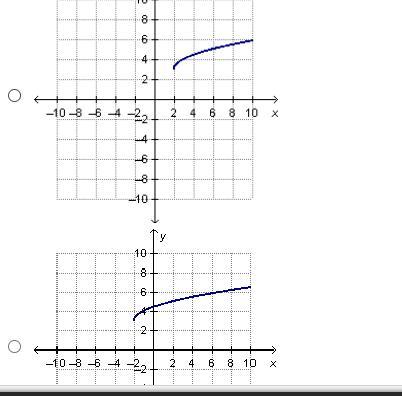
Answers
\(h(x) = \sqrt{x - 2} + 3\)
TransformationA constant inside the square root will make the graph shift either left to right, depending on the number. From the equation. The graph shifts to right two units.
A constant outside the square root will make the graph shift up or down, depending the value. From the equation, the graph shifts up 3 units.
AnswerSecond Image, the first one where x = 2 and y = 3.Answer:
Step-by-step explanation:
second graph
Solve for x. Round your answer to the nearest tenth.

Answers
Answer:
x = 11.1
Step-by-step explanation:
Cosine theta = adjacent/hypotenuse
cos 42 = x/15
x = 15 cos 42
x = 11.1
Some save me please will name brainliest if the answer is correct

Answers
Answer:
-5, -9
Step-by-step explanation:
This point is located in the fourth quadrant. When rotated at 270 degrees, it'll end up in the third quadrant. The rules for this quadrant is that both the x and y value will be negative.
Answer: I think is -9(5,)
Step-by-step explanation:
y’all please help me i’m struggglingggg

Answers
Answer:
Step-by-step explanation:
i am assuming that it wants you to find x so here is what i got.
I reccomend drawing it out
(3) 25+16÷4x= 13(x-1)
its in this formate because HI + IG will give you HG
25+4x=13x-13
25+13=13x-4x (moved the X's so they can be suptracted)
38=9x
38÷9 = 9x÷9
x≈4.2
same thing goes for the rest
(4) 16x-19+12x+9=0
16x+12x-19+9=0
28x-10=0
28x=-10/28
x= 5/14
(5) 18x-2-7x+3=0
18x-7x-2+3=0
11x-1=0
11x=1
x= 1/11
a random variable x follows a binomial distribution with mean 6 and variance 3.6. find the values of the parameters n and p
Answers
Values of parameters n and p for the binomial distribution with mean 6 and variance 3.6 are n=15 and p=0.4, respectively.
What is binomial?In probability theory and statistics, the binomial distribution is a discrete probability distribution that describes the number of successes in a fixed number of independent and identical trials, where each trial can result in only two possible outcomes, often labeled as "success" and "failure".
The distribution depends on two parameters: the probability of success (p) and the number of trials (n). The probability of getting exactly k successes in n trials can be calculated using the binomial probability mass function.
The binomial distribution has applications in various fields, including quality control, genetics, and finance, among others.
We know that for a binomial distribution, the mean and variance are given by:
Mean = np
Variance = np(1-p)
Substituting the given values, we have:
Mean = 6
Variance = 3.6
Thus, we can write two equations:
6 = np
3.6 = np(1-p)
We can solve for n and p by substituting the first equation into the second equation:
3.6 = (6/p) * (1-p) * p
3.6 = 6 - 6p
6p = 6 - 3.6
p = 0.4
Substituting this value of p into the first equation, we get:
6 = n * 0.4
n = 6 / 0.4
n = 15
Therefore, the values of the parameters n and p are n = 15 and p = 0.4, respectively.
To learn more about binomial click :
https://brainly.com/question/29163389
#SPJ1
Probability of an uncertain outcome is a number between 0 and +1, exclusively. True False
Answers
True. Probability of an uncertain outcome is a number between 0 and +1, exclusively.
The probability of an uncertain outcome is a measure of the likelihood that the outcome will occur, and it is always a number between 0 and 1, inclusive. A probability of 0 means that the event is impossible, while a probability of 1 means that the event is certain. Probabilities between 0 and 1 indicate the degree of uncertainty about whether the event will occur or not.
Probabilities cannot be negative or greater than 1, as they represent a proportion of the total possible outcomes. If the probability of an event were negative or greater than 1, it would imply that the event is impossible or certain to occur, respectively, and violate the fundamental laws of probability theory.
Learn more about Probability here
https://brainly.com/question/13604758
#SPJ11
Prove each identity below, assuming that the appropriate partial derivatives exist and are continuous. If f is a scalar field an F and G are vector fields, then F middot G, and F times G are defined by (F middot G)(x, y, z) = F(x, y, z) middot G(x, y, z) (F times G)(x, y, z) = F(x, y, z) times G(x, y, z) div (F times G) = G middot curl (F) - F middot curl (G) curl (curl(F)) = grad (div(F)) - nabla^2 F
Answers
The identities to be proven are: 1) div (F times G) = G middot curl (F) - F middot curl (G), and 2) curl (curl(F)) = grad (div(F)) - nabla^2 F.
1) To prove div (F times G) = G middot curl (F) - F middot curl (G), we can expand the divergence of the vector field F times G using the product rule. The divergence of F times G is given by div (F times G) = div(F) times G + F times div(G). Applying the curl product rule, we have curl(F times G) = G times curl(F) + F times curl(G). Taking the divergence of both sides, we get div(curl(F times G)) = G middot curl(F) + F middot curl(G). Since div(curl(F times G)) is equal to div(F times G), we conclude that div(F times G) = G middot curl (F) - F middot curl (G).
2) To prove curl(curl(F)) = grad(div(F)) - nabla^2 F, we can start by expanding the curl of F. The curl of F is given by curl(F) = (nabla cross F), and the curl of the curl of F is curl(curl(F)) = (nabla cross (nabla cross F)). Applying the vector identity for the curl of a curl, we have curl(curl(F)) = grad(div(F)) - nabla^2 F, where grad(div(F)) represents the gradient of the divergence of F and nabla^2 F represents the Laplacian of F.
By assuming that the appropriate partial derivatives exist and are continuous, we have proven the identities div (F times G) = G middot curl (F) - F middot curl (G) and curl (curl(F)) = grad (div(F)) - nabla^2 F.
Learn more about partial derivatives here:
https://brainly.com/question/28751547
#SPJ11
PLEASE HELP WILL MARK BRAINLY
(ATTACHED)


Answers
Answer:
$3.60
282.6
80
576 in
175
45
3.12
31.7
10
36
9
36
-3,√3,3,3² and √3
1/4
√64
9
1.6
4x
1
3
Step-by-step explanation:
24*.15=3.6
200=2.5*speed
speed=80
1:1/12
x:48
576 in
35=.2*x
x=175
30*1.5=45
48*.065=3.12
.5*(2π*5)=15.7
15.7+6+10=31.7
24²+a²=26²
a²=100
a=10
Pretty sure it's just 36
Volume of a cylinder :πr²*h
10*3²*π=282.6
8:12
6:x
x=9
2x+3x=90
x=18
2*18=36
-3,√3,3,3²
1/2*1/2=1/4
√64=8
3x-12+x=24 ,
4x=36
x=9
12.5w=20
w=1.6
2xy*6x²=12x³y
12x³y/(3x²y)=4x
3²+(-2)³
9-8=1
-18-6= -24
-2-2-4= -8
-24/-8=3
PLEASE HELP ME, IM BEGGING, IM ACTUALLY GOING TO CRY IF I GET THIS WRONG. A family camping in a national forest builds a temporary shelter with a tarp and a 4-foot pole. The bottom of the pole is even with the ground, and one corner is staked 5 feet from the bottom of the pole. What is the slope of the tarp from that corner to the top of the pole?
Answers
Find the mean absolute deviation (MAD) of the data in the pictograph below. Baskets
The key says one basketball picture equals two baskets. The key says one basketball picture equals two baskets. A picture graph labeled Baskets each student made. The vertical axis is labeled Baskets made. The horizontal axis is labeled Student. The names from left to right on the horizontal axis are Reynaldo, Marcelle, Allie, and Fernando. There are two basketball pictures above Reynaldo. There are four basketball pictures above Marcelle. There are three basketball pictures above Allie. There are five basketball pictures above Fernando
Answers
The mean absolute deviation (MAD) of the data in the pictograph is equals to the one basketball.
We have a data in the pictograph. In mathematics, a pictograph is a pictorial representation of data using images, icons. It is also known as a pictogram. We have a pictograph, in which the vertical axis is labeled Baskets made and the horizontal axis is labeled Student. Here, one basketball picture equals two baskets. Mean absolute deviation (MAD) is a statistical measure of the average absolute distance between each data value and the mean of a data set. It is a parameter or statistic that measures the spread, or variation, in data.
Mean is defined as the sum of data values divided by number of values.
Sum of data values = 4 + 4×2 + 3×2 + 5×2
= 28
So, mean = 28/4 = 7
Now, | 4 - 7| + |8 - 7| + |6 -7 | + | 10 - 7|
= 3 + 1 + 1 + 3 = 8
So,, mean absolute deviation (MAD) of the data = 8/7 = 1.1 ~ 1. Hence, required value is 1.
For more information about mean absolute deviations, visit :
https://brainly.com/question/26462759
#SPJ4
Complete question :
Find the mean absolute deviation (MAD) of the data in the pictograph below. Baskets
The key says one basketball picture equals two baskets. The key says one basketball picture equals two baskets. A picture graph labeled Baskets each student made. The vertical axis is labeled Baskets made. The horizontal axis is labeled Student. The names from left to right on the horizontal axis are Reynaldo, Marcelle, Allie, and Fernando. There are two basketball pictures above Reynaldo. There are four basketball pictures above Marcelle. There are three basketball pictures above Allie. There are five basketball pictures above Fernando

question what is the total number of outcomes in each situation? picking a month of the year and tossing a coin
Answers
The total number of outcomes, if one picks a month of a year, is 12 and tosses a coin is 2.
The total number of outcomes refers to the possible events that can occur if an event takes place. These are helpful in calculating probability.
The events that can occur if one picks a month of the year is he or she picks one of the following months: January, February, March, April, May, June, July, August, September, October, November, and December. Thus, the number of outcomes possible is 12.
The events that can occur if one tosses is he or she gets the following side of the coin: Heads or Tails. Thus, the number of outcomes possible is 2.
Learn more about outcome:
https://brainly.com/question/30507347
#SPJ4
find the critical value(s) and rejection region(s) for the type of z-test with level of significance . include a graph with your answer. right-tailed test, a=0.03.
Answers
Answer:
c
Step-by-step explanation:
The red line represents the critical value, and the shaded region on the right-hand side of the red line represents the rejection region. If the calculated test statistic is greater than the critical value of z, which is 1.88 in this case, we will reject the null hypothesis.
The critical value(s) and rejection region(s) for the type of z-test with a level of significance a = 0.03 and a right-tailed test are as follows :Step 1: Determine the critical value of zThe critical value is calculated by using the normal distribution table and the level of significance. A right-tailed test will have a critical value of zα. For a level of significance of 0.03, we will look for the z-value that corresponds to 0.03 in the normal distribution table.Critical value for a = 0.03 is z = 1.88 (approx).Step 2: Determine the Rejection Region The rejection region for a right-tailed test is defined as any z-value that is greater than the critical value. That is, if the test statistic is greater than 1.88, we reject the null hypothesis at the 0.03 level of significance, and if it is less than or equal to 1.88, we fail to reject the null hypothesis.Therefore, the rejection region for a right-tailed test with a level of significance of 0.03 is as follows:Rejection Region: Z > 1.88 OR Z ≤ -1.88Graph: The graph for the given values will be as follows:The red line represents the critical value, and the shaded region on the right-hand side of the red line represents the rejection region. If the calculated test statistic is greater than the critical value of z, which is 1.88 in this case, we will reject the null hypothesis.
To know more about critical value Visit:
https://brainly.com/question/32607910
#SPJ11
a professor at a local university noted that the exam grades of her students were normally distributed with a mean of 73 and a standard deviation of 11. students who made 57.93 or lower on the exam failed the course. what percent of students failed the course?
Answers
The percentage of students who failed the course is 0.25%.
To find the percentage of students who failed the course, we need to find the proportion of the distribution that is below 57.93. This can be done using the cumulative distribution function of the normal distribution.
The cumulative distribution function (CDF) of a normal distribution with mean μ and standard deviation σ is given by the following formula:
\(CDF(x) = \frac{1}{2}\times (1 + erf (\frac{x - \mu}{\sigma\times \sqrt2})\)
Where erf(z) is the error function, which is defined as:
\(erf(z) = \frac{2}{\sqrt\pi} \times \int_0^z e^{-t^2} dt\)
To find the proportion of the distribution below 57.93, we plug in the values for the mean, standard deviation, and the lower bound (57.93) into the CDF formula:
\(CDF(57.93) = \frac{1}{2} \times (1 + erf(\frac{57.93 - 73}{11 \times \sqrt2})\\= \frac{1}{2} \times (1 + erf[\frac{-3.46}{3.54}])\\= \frac{1}{2} \times (1 + erf[-0.974])\\= \frac{1}{2} \times (1 - erf[0.974])\\= \frac{1}{2} \times (1 - 0.995)\\= \frac{1}{2} \times (0.005)\\= 0.0025\\\)
This means that only 0.0025, or 0.25%, of the distribution is below 57.93. Therefore, the percentage of students who failed the course is 0.25%.
To learn more about percentage, visit:
brainly.com/question/24159063
#SPJ4
Identify the domain of this relation. {(7,9), (4,6), (8, -10), (5, -7)}
Answers
Can anyone help and tell me the measure of all 20 angles? I'm struggling. Some of them I figured out, but I'm not 100% confident that they are correct. This is a Geometry problem.

Answers
Answer:
See images
Step-by-step explanation:
When two lines cross, the angles opposite each other are equal (they are called vertical angles--different from how we use the word vertical in other math classes) The angles next to each other add up to 180° (supplementary angles)
All the angles in a triangle add up to 180°
Perpendicular lines makes right angles, those are 90°
When you have parallel lines and another line crossing them, you get 8 angles, but 4 if them are all the same. Subtract the measure from 180 and you have the measure of the other four angles. Look for a Z shape; the angles tucked inside the Z are alternate interior angles and they are equal. The alternate interior angles and their vertical angles are what make up the 4-pack of equal angles.
These are all the rules you need to know to find all 20 of the angles in your question. See images




Please help. I don’t fully understand yet!

Answers
The surface area of the cylinders are: 7794 square units, 904.9 square units, 12804 square units
What is a cylinder?recall that a cylinder is a three-dimensional solid with two parallel circular bases joined by a curved surface at a fixed distance from the center. It is considered a prism with a circle as its base and is a combination of two circles and a rectangle
the general formula for the surface area of a cylinder is
SA = 2пr(r+h)
1 SA =2*22/7*20 (20+42)
125.7(62)
SA = 7794 square units
2) SA = 2пr(r+h)
Sssurface rea = 2*3.142*9(9+7)
Surface area = 56.6(16)
Surface area = 904.9 square units
3) SA = 2пr(r+h)
surface area = 2*3.142*21(21+76)
Surface area = 132(97)
Surface area = 12804 square units
Learn more about surface area of cylinders on https://brainly.com/question/29015630
#SPJ1
Solve 3-212.
OA. x≤-30
OB. xs-18
OC. x≥-30
OD. x2-18

Answers
I hope it helps

The solution of the inequality 3-x/2≥12 is x≤-18
What is Inequality?a relationship between two expressions or values that are not equal to each other is called 'inequality.
The given inequality is 3-x/2≥12
Three minus x by two greater than or equal to twelve
Subtract 3 from both sides
-x/2≥9
-x≥18
x≤-18
Hence, the solution of the inequality 3-x/2≥12 is x≤-18
To learn more on Inequality click:
https://brainly.com/question/28823603
#SPJ7
The dependent variable is the
a.one that is expected in change based on another variable.
b.one that is thought to cause changes in another variable.
c.umber of participants in an experiment.
d.use of multiple data-gathering techniques within the same study.
Answers
The dependent variable is the :
(a) one that is expected to change based on another variable.
a. "One that is expected to change based on another variable": The dependent variable is the variable that researchers hypothesize will be influenced or affected by changes in another variable. It is the outcome or response variable that is measured or observed to determine the relationship or effect of the independent variable(s). For example, in a study investigating the impact of a new medication on blood pressure, the dependent variable would be the blood pressure measurements, which are expected to change based on the administration of the medication.
b. "One that is thought to cause changes in another variable": This describes the independent variable(s) rather than the dependent variable. The independent variable(s) are manipulated or controlled by the researcher to observe their influence or effect on the dependent variable.
c. "Number of participants in an experiment": The number of participants in an experiment refers to the sample size or the total count of individuals participating in the study. It does not represent the dependent variable, which is the variable being measured or observed to assess its relationship with the independent variable(s).
d. "Use of multiple data-gathering techniques within the same study": This option describes the methodology or approach of using multiple data-gathering techniques within a study, such as surveys, interviews, observations, or experiments. It does not define the dependent variable itself.
In summary, the correct choice for defining the dependent variable is option a. It is the variable that researchers expect to change based on another variable and is the primary focus of study in determining relationships or effects.
To learn more about dependent variable visit : https://brainly.com/question/25223322
#SPJ11
Question 5 About 9% of the population has a particular genetic mutation. 500 people are randomly selected. Find the standard deviation for the number of people with the genetic mutation in such groups of 500. Round your answer to three decimal places
Answers
Therefore, the standard deviation for the number of people with the genetic mutation in groups of 500 is approximately 6.726.
To find the standard deviation for the number of people with the genetic mutation in groups of 500, we can use the binomial distribution formula.
Given:
Probability of having the genetic mutation (p) = 0.09
Sample size (n) = 500
The standard deviation (σ) of a binomial distribution is calculated using the formula:
σ = √(n * p * (1 - p))
Substituting the given values:
σ = √(500 * 0.09 * (1 - 0.09))
Calculating the standard deviation:
σ ≈ 6.726 (rounded to three decimal places)
To know more about standard deviation,
https://brainly.com/question/12991013
#SPJ11
how many bookcases do you need for an enchanting table
Answers
Answer:
15 bookshelves
Step-by-step explanation:
For max. Hope you have a lot of exp.
15 bookshelves will max out your enchanting table. The ideal position of the bookshelves is a square of 15 placed in a 5x5-block outline, with the enchantment table in the middle.
classified company record shows that the average number of sick days taken by its employees is 4 days. you selected 200 employees for a survey and used this sample's mean number of sick days (4.8 days) as an estimate for all workers at the company. this means that group of answer choices your sample mean is biased because your sampling method tends to pick people that take more sick days. your estimator is an unbiased estimator of the population mean. if you survey more american adults, your sample mean will tend to get closer to the population mean. the distribution of the sample is likely left skewed.
Answers
Option a. Your sample mean is biased because your sampling method tends to pick people that take more sick days.
In view of the given data, the example mean of 4.8 days is more prominent than the populace mean of 4 days, which proposes that the example might be one-sided towards representatives who require more days off. This could be because of the inspecting strategy utilized or different variables that impacted the determination of the example. Nonetheless, it is as yet feasible for the assessor to be unprejudiced, intending that on typical it will give a decent gauge of the populace mean.
As additional examples are taken, the example mean is probably going to turn out to be nearer to the populace mean, yet the conveyance of the example might in any case be left-slanted, truly intending that there might be a few workers who require fundamentally more days off than others.
To learn more about sample mean, refer:
https://brainly.com/question/16043943
#SPJ4
pla shop mathematics

Answers
The number of trees more than 10m tall but not more than 20m tall is 18 trees.
How many of the trees are more than 10m tall but not more than 20m tall?0 < h ≤ 5 = 5
height greater than 0m less than or equal to 5m
5 < h ≤ 10 = 9
height greater than 5m less than or equal to 10m
10 < h ≤ 15 = 13
height greater than 10m less than or equal to 15m
15 < h ≤ 20 = 5
height greater than 15m less than or equal to 20m
20 < h ≤ 25 = 1
height greater than 20m less than or equal to 25m
The number of trees that are more than 10m tall but not more than 20m tall are;
10 < h ≤ 15 = 13
15 < h ≤ 20 = 5
So,
13 + 5 = 18 trees
Therefore, the total number of trees which are 10m tall but not more than 20m tall is 18 trees.
Read more on inequality:
https://brainly.com/question/25275758
#SPJ1
421 Students go on a field trip. There are 19 vehicles, some vans and some buses. 7 students can fit in a van, and 25 students can fit in a bus.
There were ___ buses.
There were ___ vans.
Answers
The number of vans and buses conveying the students to the field trip is 3 and 19 respectively
How to solve number of buses and Vans simultaneouslylet
number of van = xNumber of bus = yx + y = 19
7x + 25y = 421
From (1)
x = 19 - y
Substitute x = 19 - y into (2)
7x + 25y = 421
7(19 - y) + 25y = 421
133 - 7y + 25y = 421
- 7y + 25y = 421 - 133
18y = 288
y = 288/18
y = 16
Substitute y = 16 into (1)
x + y = 19
x + 16 = 19
x = 19 - 16
x = 3
Therefore, there are 3 vans and 16 buses conveying the be students to the field trip.
Read more on simultaneous equation:
https://brainly.com/question/16863577
#SPJ1
Answer this - wrong answers will be reported/deleted

Answers
Answer:
58.03 ft
Step-by-step explanation:
To solve for the total circumference of circle F, we can create a ratio of section angle measure to circumference. We know that these two attributes of a circle have a linear relationship because the formula for arc length (\(S = 2\pi r \cdot \frac{\theta}{360\°}\)) relies proportionately on the radius and angle measure of the section.
angle measure : circumference
290° : 46.75 ft
We can multiply this ratio by \(\frac{360}{290}\) to get the corresponding circumference for a 360° section (which is the entire circle).
\(\frac{360}{290}(290\° : 46.75 \text{ ft})\)
\(= 360\° : \boxed{58.03 \text{ ft}}\)
Therefore, the circumference of circle F is approximately 58.03 ft.