Raina runs each lap in 8 minutes. She will run more than 9 laps today. What are the possible numbers of minutes she will run today? Use t for the number of minutes she will run today. Write your answer as an inequality solved for t.
Answers
Considering the definition of an inequality, the number of minutes she will run today will be more than 72 minutes.
Definition of inequalityAn inequality is the existing inequality between two algebraic expressions, connected through the signs:
greater than >.less than <.less than or equal to ≤.greater than or equal to ≥.An inequality contains one or more unknown values called unknowns.
Solving an inequality consists of finding all the values of the unknown for which the inequality relation holds.
Inequality in this caseIn this case, you know that:
Raina runs each lap in 8 minutes. She will run more than 9 laps today.Being "t" the number of minutes Raina will run today, the inequality is
t÷ 8> 9
Solving:
t > 9×8
t > 72 minutes
Finally, the number of minutes she will run today will be more than 72 minutes.
Learn more about inequality:
brainly.com/question/17578702
brainly.com/question/25275758
brainly.com/question/14361489
brainly.com/question/1462764
#SPJ1
Related Questions
can someone help me please

Answers
Explanation: 5.25$ (per pound) and he wants 3 pounds so we multiply 5.25x3 which equals 15.75 and then we subtract 3.25 (because of the coupon) which makes your final answer 12.50$
Graph the system of inequalities.
U. y ≤ 4x
y+3x < 7
Answers
The line y ≤ 4x will be a solid line and shaded below the graph while the line y < -3x + 7 will be a dashed line and also shaded below the graph.
Graphing linear inequalitiesInequalities are expressions that are not separated by an equal sign. Given the following system of equations;
y ≤ 4x
y+3x < 7
The inequalities can also be written as;
y ≤ 4x
y < -3x + 7
From the linear inequalities, the slopes of the lines are 4 and -3 respectively. The line y ≤ 4x will be a solid line and shaded below the graph while the line y < -3x + 7 will be a dashed line and also shaded below the graph.
Learn more on inequality graph here: https://brainly.com/question/24372553
#SPJ1

A triangle has two sides of lengths 6 and 9. What value could the length of
the third side be? Check all that apply.
OA. 7
B. 2
C. 4
OD. 15
□E. 10
O F. 12
SUBMIT
Answers
B. 2 and OD. 15 are not possible lengths for the third side of the triangle.
To determine the possible values for the length of the third side of a triangle, we need to consider the triangle inequality theorem, which states that the sum of the lengths of any two sides of a triangle must be greater than the length of the third side.
Given that two sides have lengths 6 and 9, we can analyze the possibilities:
6 + 9 > x
x > 15 - The sum of the two known sides is greater than any possible third side.
6 + x > 9
x > 3 - The length of the unknown side must be greater than the difference between the two known sides.
9 + x > 6
x > -3 - Since the length of a side cannot be negative, this inequality is always satisfied.
Based on the analysis, the possible values for the length of the third side are:
A. 7
C. 4
□E. 10
O F. 12
B. 2 and OD. 15 are not possible lengths for the third side of the triangle.
for such more question on lengths
https://brainly.com/question/24176380
#SPJ8
Polygon V is a scaled copy of polygon U.
What is the value of w?

Answers
Answer:
w = 27
Step-by-step explanation:
the ratios of corresponding sides are in proportion, that is
\(\frac{w}{30}\) = \(\frac{36}{40}\) = \(\frac{9}{10}\) ( cross- multiply )
10w = 9 × 30 = 270 ( divide both sides by 10 )
w = 27
27
Step-by-step explanation:
Since polygon V is a scaled copy of polygon U the scale ratio of similar side is equal.
Hence 40÷36=20÷18=30÷w
40÷36=1.1111111
therefore 30÷w=1.111111
so W=30÷1.11111111=27.000027
W=27
In august, emily's clothing store sold 520 shirts with the ratio of short sleeve to long sleeve being 3:7. How many short sleeve shirts were sold?
Answers
156 short sleeve shirts were sold in Emily's clothing store during the given period.
To determine the number of short sleeve shirts sold in Emily's clothing store, we need to calculate 3/10 of the total number of shirts sold, since the ratio of short sleeve to long sleeve shirts is 3:7.
We know that the total number of shirts sold is 520. To find 3/10 of 520, we multiply 520 by 3/10:
3/10 * 520 = (3/10) * 520 = (3 * 520) / 10 = 1560 / 10 = 156
Therefore, 156 short sleeve shirts were sold in Emily's clothing store in August.
Alternatively, we can solve this problem using proportions. If we set up the proportion:
(3/10) = x/520,
where x represents the number of short sleeve shirts sold, we can cross-multiply to find:
10x = 3 * 520,
10x = 1560,
x = 156.
Hence, 156 short sleeve shirts were sold in Emily's clothing store during the given period.
Know more about Ratio's here:
https://brainly.com/question/31945112
#SPJ11
what is the solution for the equation y=1/4x-7
Answers
Answer:
There are an infinate amount of solutions
Step-by-step explanation:
3. Find the slope and y-intercept of the graph of the following equation.
2y + 4 = -6x
Answers
Answer:
slope= -3,y - intercept y = -2
Step-by-step explanation:
- Make y the subject by taking four on the opposite side of the equal sign.
2y = -6x - 4
- Divide throughout by 2 and from there you get the gradient which is also the slope.
- To get the y - intercept,the value of x =0. Thus you get y =-2.
What is the simplified expression for 6(2(y+x))
Answers
Distribute
12y+12x
Answer
12y+12x
Answer:
12x + 12y
yup
find the coordinates of A' after a reflection across the y-axis and then across the line y = -2. write your answer in the form (a, b).

Answers
Answer:
(3,1)
Step-by-step explanation:
When a point is reflected across the y axis, the sign of its x coordinate flips. Since point A is at (-3,-5), when it is reflected across the y axis its new position will be (3,-5). Now, point A is 3 units from the line y=-2, meaning that when it is reflected across it will be 3 units away from the other direction. (-2+(3))=1, meaning that the final coordinates of point A are (3,1). Hope this helps!
Please explain in detail
4. Software architecture has been standardized to have five architectural segments and two application program interfaces. The architectural segments include operating system (OS), I/O services (IOS),
Answers
The given information states that software architecture has been standardized to include five architectural segments, namely the operating system (OS), I/O services (IOS), and three additional segments not specified.
Software architecture has been standardized to have five architectural segments and two application program interfaces (APIs). The architectural segments consist of the operating system (OS), I/O services (IOS), and three additional segments that are not specified in the given information. These segments are typically designed to handle specific functionalities or components of the software system.
The operating system (OS) segment is responsible for managing the hardware resources and providing essential services to the software applications. It handles tasks such as memory management, process scheduling, file system management, and device drivers. The I/O services (IOS) segment is responsible for handling input and output operations, such as user interaction, data transfer between external devices and the software system, and file I/O operations.
The two application program interfaces (APIs) provide a means for different software components or modules to communicate and interact with each other. APIs define a set of functions, protocols, and data structures that enable the exchange of information and services between different software entities. They serve as an abstraction layer, allowing developers to build upon existing functionality without needing to understand the underlying implementation details.
Learn more about segments here:
brainly.com/question/29628993
#SPJ11
Grace made $3,300 in interest by placing $10,000 in a savings account with simple interest
for 3 years. What was the interest rate?
Answers
Answer:
11% interest rate
Step-by-step explanation:
3,300 / 3 = 1,100
$1,100 per year
1,100 / 10000
.11 = 11%
You perform a Chi-Square test and obtain a p-value lower than 0.01. What does that mean?
Answers
Performing a Chi-Square test is a statistical tool used to determine if there is a significant difference between observed and expected data. The test helps to analyze categorical data by comparing observed frequencies to the expected frequencies. The p-value in a Chi-Square test refers to the probability of obtaining the observed results by chance alone.
If a p-value lower than 0.01 is obtained in a Chi-Square test, it means that the results are statistically significant. In other words, there is strong evidence to reject the null hypothesis, which states that there is no significant difference between the observed and expected data. This means that the observed data is not due to chance alone, but rather to some other factor or factors.
The mean, or average, is not directly related to the Chi-Square test or the p-value. The Chi-Square test is specifically used to determine the significance of the observed data. However, the mean can be used as a measure of central tendency for continuous data, but it is not applicable to categorical data.
In conclusion, obtaining a p-value lower than 0.01 in a Chi-Square test means that there is strong evidence to reject the null hypothesis, and that the observed data is statistically significant.
learn more about Chi-Square here: brainly.com/question/24976455
#SPJ11
A bag contains 4 blue coins and 7 red coins. A coin is removed at random and placed by three of the other color.
What is the probability that the removed coin is blue?
Answers
Answer:
The probability is 7/11
Step-by-step explanation:
This is because there are 7 blue coins that you can grab out of 11 coins in total.
complete the rule for the transformation shown in the table below. Grab the original figure and transformed figure on the coordinate plane. Describe the transformations applied in words

Answers
Notice that:
\(\begin{gathered} (5,-3)=(1+4,-1*3), \\ (6,0)=(2+4,-1*0), \\ (8,-1)=(4+4,-1*1). \end{gathered}\)Therefore the rule for the given transformation is:
\((x,y)\to(x+4,-y).\)The graph of the original points is:
The graph of the transformed points is:
Notice that the points are reflected over de x-axis and then translated 4 units to the right.
Answer:
\((x,y)\to(x+4,-y).\)The points are reflected over de x-axis and then translated 4 units to the right.



for shape (i) give the electron-domain geometry on which the molecular geometry is based.
Answers
In shape (i), there are two electron domains around the central atom. This means that the electron-domain geometry is linear. However, there are two bonding pairs and no lone pairs of electrons around the central atom, resulting in the molecular geometry also being linear.
The concept of electron-domain geometry and molecular geometry is essential in understanding the properties of molecules. The electron-domain geometry is determined by the number of electron domains (bonding or lone pairs) around the central atom in a molecule. On the other hand, the molecular geometry is determined by the arrangement of atoms in the molecule, taking into account the presence of lone pairs.
Knowing the electron-domain geometry and molecular geometry of a molecule is crucial in predicting its polarity and reactivity. For instance, polar molecules have an asymmetric distribution of electron density, while nonpolar molecules have a symmetric distribution. This difference in polarity affects the physical and chemical properties of a molecule, such as boiling point, melting point, and solubility.
In summary, in shape (i), both the electron-domain geometry and molecular geometry are linear, which means that the central atom has two bonding pairs and no lone pairs. Understanding the electron-domain and molecular geometry of molecules is essential in predicting their properties and behavior.
To know more about electron domains refer here:
https://brainly.com/question/30461548?#
SPJ11
For the function f(x) = 2x-4/x+3
What is the x-intercept, y-intercept, and vertical asymptotes
Answers
Answer:
x-intercept: (2,0)
y-intercept: (0,-4/3)
vertical asymptote: x = -3
Step-by-step explanation:
To find the x-intercepts, we can set f(x) to 0, which is y=0:
2x-4/x+3 = 0
2x-4 = 0
2x = 4
x = 2
To find the y-intercepts, we can set x to 0:
2(0)-4/(0)+3 = y
y = -4/3
To find the vertical asymptote, we can set the denominator equal to 0:
x+3 = 0
x = -3
Information for questions 13-18: An insurance company determines that a linear relationship exists between the cost of fire damage in major residential fires and the distance from the house to the nearest fire station. A sample of 20 recent fires in a large suburb of a major city was selected. For each fire, the following variables were recorded: x= the distance between the fire and the nearest fire station (in miles) y= cost of damage (in dollars) The distances between the fire and the nearest fire station ranged between 0.6 miles and 6.2 miles
Answers
Based on the distance of residential properties from fire stations, this study aims to provide insights and empirical evidence to help insurance companies decide on premiums, risk assessments, and resource allocation.
A concentrate on major private flames in an enormous suburb of a significant city was done by the insurance agency. The distance between the house and the nearest fire station was found to have a straight relationship with the expense of fire harm.
The distance (x) between the fire and the nearest fire station, estimated in miles, and the expense of harm (y), communicated in dollars, were recorded for every one of twenty ongoing flames. The measured distances ranged from 0.6 miles to 6.2 miles.
The study's objective is to investigate how fire damage costs change as you move further away from the fire station. Insurance companies will be able to better allocate resources and assess risk thanks to this.
To know more about expense refer to
https://brainly.com/question/29850561
#SPJ11
The cold wind causes us to feel the air temperature cold. This is called the cooling effect of the wind. Wind with a speed of 60 km per hour causes the air temperature to feel 8 ° C cooler in Ağrı. When the air temperature in Ağrı is -3 ° C, how many degrees is the air temperature felt?
Answers
Answer:
The air temperature is felt at -11 ºC.
Step-by-step explanation:
According to the statement, wind flow causes that air temperature is apparently lower than real temperature. If wind causes the air temperature to feel 8 ºC cooler in Ağrı and real temperature is -3 ºC, then the apparent temperature is:
\(T = -3\,^{\circ}C -8\,^{\circ}C\)
\(T = -11\,^{\circ}C\)
The air temperature is felt at -11 ºC.
Help pls
1. Renae has been playing Tower of Hanoi and has noticed that the minimum number of moves it takes to defeat the game is related to the number of disks she must move. She has recorded her observations below. Write an equation that describes this pattern.
2. Use a proof by mathematical induction to show that your equation from question 1 applies to the minimum number of moves required to defeat the Tower of Hanoi game, based on the number of disks you must move. Think about the process of the game; and describe how your equation applies to it.

Answers
The minimum number of moves required to solve the Tower of Hanoi puzzle with n disks is given by the formula n = 2(n -1) + 1.
What is central limit theorem?The central limit theorem, a cornerstone of statistics, asserts that, regardless of the population's underlying distribution, the distribution of sample means tends towards normality as sample size grows. In other words, as sample size rises, the distribution of sample means will become more normal, even if the population is not normally distributed. This is a significant finding because, on the assumption that the sample is representative and randomly chosen, it enables us to draw conclusions about the population from a sample size that is rather small.
From the given table we observe the following pattern:
number of moves(n) = 2 * number of moves(n-1) + 1
Hence, the minimum number of moves required to solve the Tower of Hanoi puzzle with n disks is given by the formula n = 2(n -1) + 1.
Learn more about sequence here:
https://brainly.com/question/21961097
#SPJ1
Identify the quadrant or axis that the following points lie on, if the point lies on an axis, specify which part (positive or negative) of which axis (X or Y)

Answers
Given point (-1, 9), we should determine the quadrant it belongs to and also determine which is positive or negative between x and y.
from the above graph, we can see that the point is in the first quadrant.
x is negative
y is positive

Find 15.75 ÷ 0.25 using a Giant One.
Answers
Answer:
its 63
Step-by-step explanation:
Answer:
\( \frac{15.75}{0.25} = \frac{1575}{25} \\ = 63\)
...............................
an engineer has designed a valve that will regulate water pressure on an automobile engine. the valve was tested on 100 engines and the mean pressure was 5.5 lbs/square inch. assume the standard deviation is known to be 0.7 . if the valve was designed to produce a mean pressure of 5.3 lbs/square inch, is there sufficient evidence at the 0.05 level that the valve performs above the specifications? state the null and alternative hypotheses for the above scenario.
Answers
There is sufficient evidence that the valve performs above the specifications.
Null Hypothesis (H0): The mean pressure of the valve is equal to 5.3 lbs/square inch
Alternative Hypothesis (H1): The mean pressure of the valve is greater than 5.3 lbs/square inch
To test whether the valve performs above the specifications, a hypothesis test can be used. The test statistic used will be a t-test since the sample size is below 30. The critical value at the 0.05 level is 1.645. The formula for the t-test is: t = (X-μ)/(s/√n) , where X is the sample mean, μ is the population mean, s is the sample standard deviation, and n is the sample size.
Plugging in the known values, the t-test is calculated as: t = (5.5-5.3)/(0.7/√100) = 2.571. Since this value is greater than the critical value at the 0.05 level (1.645), we can reject the null hypothesis and conclude that there is sufficient evidence that the valve performs above the specifications.
Learn more about test statistic here:
https://brainly.com/question/14128303
#SPJ4
need help with everything but if you can only help me woth 1 is fine

Answers
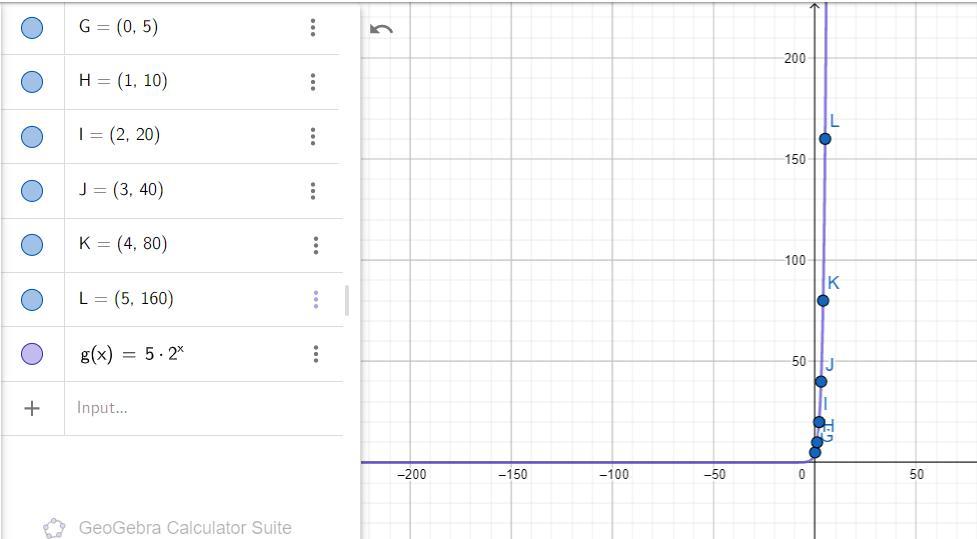
From linear function data, we have
From exponential function data, we have
The major distinction between linear and exponential functions is the rate of their growth.
Linear growth is always at the same rate, whereas exponential growth increases exponentially over time.

As a general rule in computing the standard error of the sample mean, the finite population correction factor is used only if the:
Group of answer choices
1. sample size is more than half of the population size.
2. sample size is smaller than 5% of the population size.
3. sample size is greater than 5% of the sample size.
4. None of these choices.
Answers
The finite population correction factor is used in computing the standard error of the sample mean when the sample size is smaller than 5% of the population size.
The finite population correction factor is a adjustment made to the standard error of the sample mean when the sample is taken from a finite population, rather than an infinite population.
It accounts for the fact that sampling without replacement affects the variability of the sample mean.
When the sample size is relatively large compared to the population size (more than half), the effect of sampling without replacement becomes negligible, and the finite population correction factor is not necessary.
In this case, the standard error of the sample mean can be estimated using the formula for sampling with replacement.
On the other hand, when the sample size is small relative to the population size (less than 5%), the effect of sampling without replacement becomes more pronounced, and the finite population correction factor should be applied.
This correction adjusts the standard error to account for the finite population size and provides a more accurate estimate of the variability of the sample mean.
Therefore, the correct answer is option 2: the finite population correction factor is used when the sample size is smaller than 5% of the population size.
Learn more about mean here:
https://brainly.com/question/31101410
#SPJ11
Given circle O shown, find the following measurements. Round your answers to the nearest whole number. Use 3.14 for π .

Answers
In the given diagram of circle O, we need to find various measurements. Let's consider the following measurements:
Diameter (d): The diameter of a circle is the distance across it, passing through the center. To find the diameter, we can measure the distance between any two points on the circle that pass through the center. Let's say we measure it as 12 units.
Radius (r): The radius of a circle is the distance from the center to any point on the circumference. It is half the length of the diameter. In this case, the radius would be 6 units (12 divided by 2).
Circumference (C): The circumference of a circle is the distance around it. It can be found using the formula C = 2πr, where π is approximately 3.14 and r is the radius. Using the radius of 6 units, we can calculate the circumference as C = 2 * 3.14 * 6 = 37.68 units. Rounding to the nearest whole number, the circumference is approximately 38 units.
Area (A): The area of a circle is the measure of the surface enclosed by it. It can be calculated using the formula A = πr^2. Substituting the radius of 6 units, we can find the area as A = 3.14 * 6^2 = 113.04 square units. Rounding to the nearest whole number, the area is approximately 113 square units.
In summary, for circle O, the diameter is 12 units, the radius is 6 units, the circumference is approximately 38 units, and the area is approximately 113 square units.
For more such questions on various measurements
https://brainly.com/question/27233632
#SPJ8
WILL MARK BRAINLIEST
Nilsa is working on a 60-minute math test. There are 20 questions on the test. If it takes her 20 minutes to complete 12 of the questions, what is the greatest amount of time on average she can spend on each of the remaining 8 questions?

Answers
Answer: 5 minutes
60 minutes to start -20 minutes used =40 minutes left
40 minutes left/ 8 questions = 5 minutes on average per question
Find the value 3x-7 if 4x+12=24
Answers
I'm pretty sure that's what you meant

If Jada runs 5 laps around the track in 6 minutes how many minutes per lap is that
Answers
Answer:
1.2 minutes
Step-by-step explanation:
5 laps >> 360 ( 6×60)
1 lap >> x
cross multiplication
5x = 360
x = 360/5
x= 72 second
x = 72/60 = 1.2 minute
Consider a three-category classification problem. Let the prior probabilities: p(Y = 1) = p(Y = 2) = p(Y = 3) = 1/3. The class-conditional densities are multivariate normal densities with parameters: Mi = [0,0], M2 = [1,1]], M3 = (-1,1], = and Σ : 1 0.7 0 0 0.7 ], = Σ2 = 1 0.8 0.2 0.2 0.8 1 Σ3 1 0.8 0.2 0.2 0.8 > Classify the following point x = (0.5, 0.5].
Answers
We classify x as belonging to class 1, since it has the highest posterior probability.
To classify the point x = (0.5, 0.5], we need to calculate the posterior probabilities of each class and choose the class with the highest probability.
The posterior probability of class i given x is given by Bayes' theorem:
P(Y=i|X=x) = P(X=x|Y=i) * P(Y=i) / P(X=x)
where P(X=x|Y=i) is the class-conditional density of class i evaluated at x, P(Y=i) is the prior probability of class i, and P(X=x) is the marginal probability of x (which is the same for all classes in this case).
Using the multivariate normal density formula, we can calculate the class-conditional densities as follows:
f1(x) = (2π|Σ1|)-1/2 exp{-1/2(x-M1)'Σ1^-1(x-M1)} = (2π|Σ1|)-1/2 exp{-1/2(0.5^2+0.5^2)}
f2(x) = (2π|Σ2|)-1/2 exp{-1/2(x-M2)'Σ2^-1(x-M2)} = (2π|Σ2|)-1/2 exp{-1/2[(0.5-1)^2+(0.5-1)^2+2*0.2*(0.5-1)*(0.5-1)]}
f3(x) = (2π|Σ3|)-1/2 exp{-1/2(x-M3)'Σ3^-1(x-M3)} = (2π|Σ3|)-1/2 exp{-1/2[(0.5+1)^2+(0.5-1)^2+2*0.2*(0.5+1)*(0.5-1)]}
Using the given prior probabilities, we have P(Y=1) = P(Y=2) = P(Y=3) = 1/3.
To calculate the b P(X=x), we can use the total probability theorem:
P(X=x) = Σi P(X=x|Y=i) * P(Y=i) = f1(x)*1/3 + f2(x)*1/3 + f3(x)*1/3
Now we can calculate the posterior probabilities:
P(Y=1|X=x) = f1(x)*1/3 / P(X=x)
P(Y=2|X=x) = f2(x)*1/3 / P(X=x)
P(Y=3|X=x) = f3(x)*1/3 / P(X=x)
To classify x, we choose the class with the highest posterior probability:
argmaxi P(Y=i|X=x)
Calculating the posterior probabilities and choosing the maximum, we get:
P(Y=1|X=x) = 0.6356
P(Y=2|X=x) = 0.2113
P(Y=3|X=x) = 0.1531
Learn more about Bayes' theorem here:
https://brainly.com/question/29598596
#SPJ11
It has been claimed that the best predictor of todays weather is todays weather. Suppose in the town of Octapa, if it rained yesterday, then there is a 60% chance of rain today, and if it did not rain yesterday there is an 85% chance of no rain today. A) find the transition matrix describing the rain probabilities. B) if it rained monday, what is the probability it will rain Wednesday? C) if it did not rain Friday, what is the probability of rain Monday? D) using the matrix from A. find the steady-state vector. use this to determine the probability that it will be raing at the end of time.
Answers
Therefore, the probability that it will be raining at the end of time is 37.5%.
A) To describe the transition matrix, we can use the following notation: R = It will rain N = It will not rain
Since it is given that if it rained yesterday, then there is a 60% chance of rain today, and if it did not rain yesterday there is an 85% chance of no rain today.
Thus, the transition matrix would be as follows:| P(R/R) P(N/R)| P(R/N) P(N/N)| = |0.6 0.4| |0.15 0.85|
B) If it rained Monday, then we need to find the probability that it will rain Wednesday.
We can find this by multiplying the probability of rain on Wednesday given that it rained on Monday and the probability that it rained on Monday.
Thus, the probability of rain on Wednesday, given that it rained on Monday would be:0.6 x 0.6 = 0.36So, there is a 36% chance that it will rain on Wednesday given that it rained on Monday.
C) If it did not rain Friday, then we need to find the probability of rain on Monday. Using Bayes' theorem, we can write: P(R/M) = P(M/R)P(R)/[P(M/R)P(R) + P(M/N)P(N)]where, M = It did not rain Friday= 0.15 (from the transition matrix)P(R) = Probability of rain = 0.6 (given in the problem)P(N) = Probability of no rain = 0.4 (calculated from 1 - P(R))P(M/R) = Probability of it not raining on Friday given that it rained on Thursday = 0.4P(M/N) = Probability of it not raining on Friday given that it did not rain on Thursday = 0.85Substituting these values, we get: P(R/M) = 0.4 x 0.6/[0.4 x 0.6 + 0.85 x 0.4] = 0.31 So, there is a 31% chance of rain on Monday given that it did not rain on Friday.
D) The steady-state vector is the vector that describes the probabilities of being in each of the states in the long run. To find the steady-state vector, we need to solve the following equation: πP = πwhere,π = steady-state vector P = transition matrix Substituting the values from the transition matrix, we get:| π(R) π(N)| |0.6 0.4| = | π(R) π(N)| | π(R) π(N)| |0.15 0.85| | π(R) π(N)|
Simplifying this, we get the following two equations:π(R) x 0.6 + π(N) x 0.15 = π(R)π(R) x 0.4 + π(N) x 0.85 = π(N) Solving these equations, we get: π(R) = 0.375π(N) = 0.625So, the steady-state vector is:| π(R) π(N)| = |0.375 0.625|This means that in the long run, there is a 37.5% chance of rain and a 62.5% chance of no rain.
To Know more about probability visit:
https://brainly.com/question/31828911
#SPJ11