The graph below shows the average daily temperatures on January 1 from 1900 to 1934 for city A.
A graph shows the average daily temperature on the x-axis, and number of years on the y-axis, from 1 to 4. The average temperature was 18 for 2 years; 19 for 3 years; 20 for 2 years; 21 for 3 years; 22 for 2 years; 23 for 4 years; 24 for 3 years; 25 for 3 years; 26 for 5 years; 27 for 2 years; 28 for 1 year; 29 for 2 years; 30 for 2 years; 31 for 1 year.
The mean of the temperatures in the chart is 24° with standard deviation of 4°. How many years had temperatures within one standard deviation of the mean?
Answers
On the graph of average daily temperatures, the temperature that is within one standard deviation of the mean is 22 degrees Celsius. The difference between the highest value and the data set's mean, divided by two, is the standard deviation.
What are the data's mean and standard deviation?The average value of the provided data is known as the data's mean. The difference between the highest value and the data set's mean, divided by two, is the standard deviation. The graph below in the accompanying image displays the typical daily temperatures for city A on January 1 from 1900 to 1934.On a graph, the x-axis represents the average daily temperature, and the y-axis lists the years from 1 to 4.When the mean is and the standard deviation is, the interval that is within standard deviations of the mean can be as given,The temperatures in the graph have a mean of 24° and a standard deviation of 4°. If you enter these values, the temperatures in the available options—which fall within the range above—will be correct.The temperature on the graph of average daily temperatures that is within one standard deviation of the mean is 22 degrees Celsius.To learn more about Standard deviation refer to:
https://brainly.com/question/475676
#SPJ1
Answer: 22 degrees
Step-by-step explanation:
i think
Related Questions
Given a standardized normal distribution with a mean of 0 and standard deviation of 1, what is the probability that
A) Z is less than 1.08
B) Z is greater that -0.21
C) Z is less than -0.21 or greater than the mean
D) Z is less than -0.21 or greater than 1.08
Answers
Option - D : Given a standardized normal distribution with a mean of 0 and standard deviation of 1, the probability that Z is less than -0.21 or greater than 1.08
A) To determine the likelihood that Z is less than 1.08, we check up the value of 1.08 in the table of the ordinary normal distribution or use a calculator to determine that the likelihood is around 0.8599 or 85.99%.
B) We may use a calculator or the conventional normal distribution table to determine the chance that Z is bigger than -0.21 and discover that it is around 0.5832, or 58.32%.
C) We may combine the probabilities of Z being less than -0.21 and Z being more than 0 to get the likelihood that Z is less than -0.21 or greater than the mean (0). We discover the following using a calculator or the conventional normal distribution table:
P(Z < -0.21) = 0.4168
P(Z > 0) = 0.5
So, the probability that Z is less than -0.21 or greater than the mean is:
P(Z < -0.21 or Z > 0) = P(Z < -0.21) + P(Z > 0) = 0.4168 + 0.5 = 0.9168 or 91.68%.
D) To find the probability that Z is less than -0.21 or greater than 1.08, we can add the probability of Z being less than -0.21 to the probability of Z being greater than 1.08. Using standard normal distribution table,we find:
P(Z < -0.21) = 0.4168
P(Z > 1.08) = 0.1401
thus the probability that Z is less than -0.21 or greater than 1.08 is:
P(Z < -0.21 or Z > 1.08) = P(Z < -0.21) + P(Z > 1.08) = 0.4168 + 0.1401 = 0.5569 or 55.69%.
For such more questions on standardized normal distribution:
brainly.com/question/29509087
#SPJ4
how many different license plates can be formed if each plate plate has 5 different digits followed by 1 letter
Answers
This is a fundamental counting principle problem and can be solved by multiplying the number of choices you have for each digit of the license plate.
For the first five digits you can choose from the numbers 0,1,2...,9 or 10 choices.
A we cannot repeat the digits, so, first five digits will be:
10 × 9 × 8 × 7 × 6
Now the next 1 digit will all be letter all being different
There are 26 letters in the alphabet.. for our second digit we have 26 choices,
Here is the whole calculation:
= 10 × 9 × 8 × 7 × 6 × 26
= 786240
To learn more about calculating possibilities from the given link
brainly.com/question/4658834
#SPJ4
Express the followings as functions of r and 0, when z = x+iy=r(cos+isin). You are required to show calculation details to answer for each of the questions. [10 pts] Ər do A. B. əx Əx
Answers
A. ∂r/∂x = cos θ.
B. ∂x/∂r = cos θ.
To express the following functions in terms of r and θ (or 0):
A. ∂r/∂x
We have z = x + iy = r(cos θ + i sin θ)
To find ∂r/∂x, we differentiate the real part of z with respect to x, keeping θ constant.
∂r/∂x = ∂(r cos θ)/∂x = cos θ
Therefore, ∂r/∂x = cos θ.
B. ∂x/∂r
To find ∂x/∂r, we need to express x in terms of r and θ.
From z = x + iy = r(cos θ + i sin θ), we can isolate x:
x = r cos θ
Now we differentiate x with respect to r, keeping θ constant.
∂x/∂r = ∂(r cos θ)/∂r = cos θ
Therefore, ∂x/∂r = cos θ.
Note: In both cases, the derivative with respect to θ (or 0) is 0 because the functions do not depend on θ (or 0).
Learn more about functions from
https://brainly.com/question/11624077
#SPJ11
what is the answer i need help

Answers
Answer:
\(588mm^3\)
Step-by-step explanation:
Each side of the blue pyramid is 3 times the size of the red pyramid.
Instead of just dividing by 3 for the volume we must divide by 9 instead because we're working in cubes.
The graph represents a function related to a train's movement over time.
12
11
10
9
8
6
5
4
2
0 1 2 3 4
7 8 9 10 11 12
Time
Which function could this graph represent?
A.
the speed of a train as it decreases its rate of acceleration
B.
the speed of a train as it slows down when approaching a station
C.
the distance of a train from a station it has departed as it accelerates
D.
the distance of a train from a station it approaches at a constant speed
Answers
Answer:
Where is the question?
Step-by-step explanation:
Evaluate the expression: 3c - 6d where c = 7 and d = -4
Answers
Answer:
45
Step-by-step explanation:
(3)(7)−(6)(−4)
=21−(6)(−4)
=21−(−24)
=45
find the area of the polygon with the given vertices x(2,4) y(0,-2) z(2,-2)
Answers
Answer:
6
Step-by-step explanation:
b = 2 units
h = 6 units
A=1/2 *b*h
= 1/2 *6*2
= 6
Given that lim f(x) = 9 lim g(x) = -4 lim h(x) = 0, X-2 X-2 X-2 find each limit, if it exists. (If an answer does not exist, enter DNE.) (a) lim [f(x) + 4g(x)] X-2 (b) lim [g(x)]³ X-2 (c) lim √f(x)
Answers
To find the limits of the given expressions, we can use the properties of limits. Given that lim f(x) = 9, lim g(x) = -4, and lim h(x) = 0 as x approaches 2, we can determine the limits of (a) [f(x) + 4g(x)], (b) [g(x)]³, and (c) √f(x) as x approaches 2.
(a) To find lim [f(x) + 4g(x)] as x approaches 2, we can apply the limit properties. Since lim f(x) = 9 and lim g(x) = -4 as x approaches 2, we can substitute these values into the expression to get lim [f(x) + 4g(x)] = 9 + 4(-4) = 9 - 16 = -7.
(b) To find lim [g(x)]³ as x approaches 2, we again apply the limit properties. Since lim g(x) = -4 as x approaches 2, we can substitute this value into the expression to get lim [g(x)]³ = (-4)³ = -64.
(c) To find lim √f(x) as x approaches 2, we can apply the limit properties. Since lim f(x) = 9 as x approaches 2, we can substitute this value into the expression to get lim √f(x) = √9 = 3.
In summary, the limits are: (a) -7, (b) -64, and (c) 3.
Learn more about limits here
https://brainly.com/question/12211820
#SPJ11
Find the derivative.
y = x sinhâ¹(x/3) â â(9 + x²)
Answers
The derivative of the function y = x sinh(x/3) - (9 + x²) is ln((x + √(x² + 9))/3) + (x/(3√(x² + 9))) - 2x.
To find the derivative of y = x sinh⁻¹(x/3) - (9 + x²), we will use the chain rule and the power rule of differentiation.
First, we can simplify the expression by using the identity sinh⁻¹(x) = ln(x + √(x² + 1)), so we have:
y = x ln(x/3 + √((x/3)² + 1)) - (9 + x²)
Now we can differentiate term by term, using the chain rule for the first term:
y' = ln(x/3 + √((x/3)² + 1)) + x(1/(x/3 + √((x/3)² + 1))) (1/3) - 2x
Simplifying the first term and combining like terms in the second term, we get:
y' = ln((x + √(x² + 9))/3) + (x/(3√(x² + 9))) - 2x
This is the final answer for the derivative of y.
Learn more about the derivative at
https://brainly.com/question/25324584
#SPJ4
The question is -
Find the derivative of the function y = x sinh(x/3) - (9 + x²).
compared to white americans of european descent, african americans score, on average, 1. about 5 points lower on iq tests. 2. about 5 points higher on iq tests. 3. about 10 points lower on iq tests. 4. about 15 points lower on iq tests. 5. about the same on iq tests.
Answers
According to the statement is:
About 15 points lower on IQ tests.
The correct option is (4)
In the United States, almost no one can trace their ancestry back to just one place. And for many, the past may hold some surprises, according to a new study. Researchers have found that a significant percentage of African-Americans, European Americans, and Latinos carry ancestry from outside their self-identified ethnicity. The average African-American genome, for example, is nearly a quarter European, and almost 4% of European Americans carry African ancestry.
The average African-American genome, for example, is 73.2% African, 24% European, and 0.8% Native American, the team reports online today in The American Journal of Human Genetics. Latinos, meanwhile, carry an average of 18% Native American ancestry, 65.1% European ancestry (mostly from the Iberian Peninsula), and 6.2% African ancestry.
So, The correct option is (4)
About 15 points lower on IQ tests.
Learn more about Average at:
https://brainly.com/question/24967042
#SPJ4
PLS THIS IS TIMED! I WILL GIVE BRAINLIEST!!!!

Answers
Answer:
the answer is y= 5(0.25)^x or C
Step-by-step explanation:
Without calculation, find one eigenvalue and two linearly independent eigenvectors of A =2 2 2 Justify your answer. 2 2 2 One eigenvalue of A is A = 0 because the columns of A are linearly dependent. 1 1 Two linearly independent eigenvectors of A are because the entries of each vector sum to 0. 1 -1 2 0 (Use a comma to separate answers as needed.)
Answers
The two vectors are linearly independent because their dot product is 0.
Answer:Without calculation, the eigenvalue of A = [2 2 2; 2 2 2; 1 1 0] and two linearly independent eigenvectors are: The eigenvalue of A is 0 because the columns of A are linearly dependent.Two linearly independent eigenvectors of A are:1 1 -21 -1 20 The eigenvector corresponding to the eigenvalue λ = 0 is the nullspace of A, since A(0) = 0.The null space of A is given by the solution set of the system Ax = 0,
which yields:x1 = -x2x3 = 0 The solution set is a line passing through the origin spanned by the vector x = [1, -1, 0]T, which is one eigenvector.The other eigenvector can be chosen to be orthogonal to x, which can be achieved by choosing x = [1, 1, -2]T / sqrt (6). The two vectors are linearly independent because their dot product is 0.
Learn more about Vectors
brainly.com/question/29740341
#SPJ11
Jason reads for 90 minutes each day Which equation can be used to solve for m the number of minutes Jason reads in 3 days
Answers
Answer:
90(3) = m or 90 x 3 = m
Step-by-step explanation:
90 minutes per day for 3 days
Find the population standard deviation by hand for the following
data set: 10,12, 8(do not use your calculator)
Answers
The population standard deviation for the given data set is approximately 1.6329.
To find the population standard deviation by hand, you need to follow these steps:
1. Calculate the mean (average) of the data set:
Mean = (10 + 12 + 8) / 3 = 30 / 3 = 10
2. Calculate the deviation of each data point from the mean:
Deviation for 10: 10 - 10 = 0
Deviation for 12: 12 - 10 = 2
Deviation for 8: 8 - 10 = -2
3. Square each deviation:
Squared deviation for 10: 0^2 = 0
Squared deviation for 12: 2^2 = 4
Squared deviation for 8: (-2)^2 = 4
4. Calculate the sum of squared deviations:
Sum of squared deviations = 0 + 4 + 4 = 8
5. Divide the sum of squared deviations by the total number of data points (in this case, 3) to get the variance:
Variance = 8 / 3 ≈ 2.6667
6. Take the square root of the variance to find the population standard deviation:
Population standard deviation = √2.6667 ≈ 1.6329
Therefore, the population standard deviation for the given data set is approximately 1.6329.
learn more about mean here: brainly.com/question/31101410
#SPJ11
Answers with reasons pls.

Answers
Answer:
a=96 b=104 c=85
Step-by-step explanation:
If you use Interior angles and vertical angles theorem you can solve it
Find the distance between each pair of points
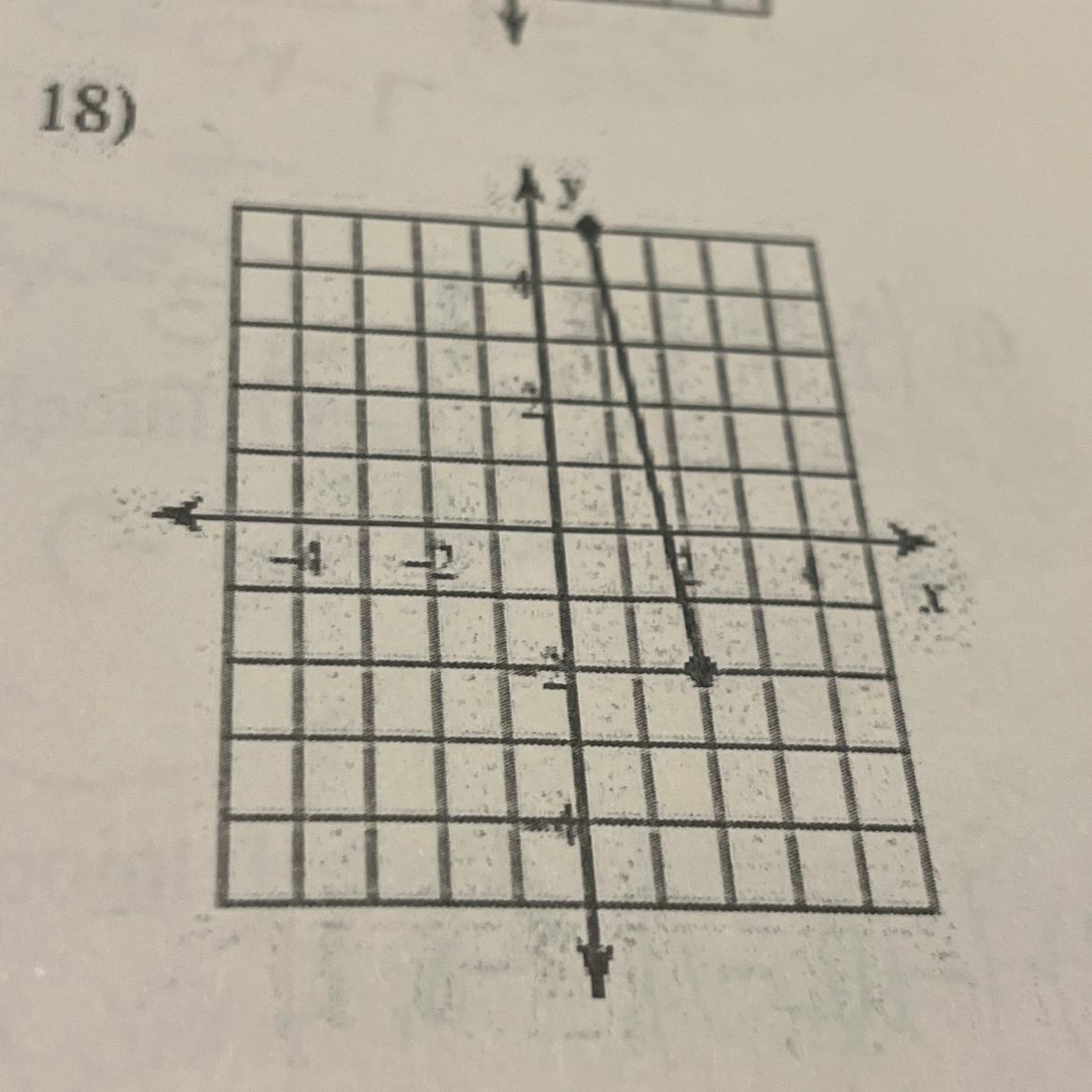
Answers
Answer:
7.071068 ≈ 7.07
Step-by-step explanation:
The distance, d, between 2 points (x1, y1) and (x2, y2) is given by the formula
\(d = \sqrt {(x_{2} - x_{1})^2 + (y_{2} - y_{1})^2}\)
The two points as determined from the graph are (1, 5) and (2, -2)
\(d = \sqrt {(2 - 1)^2 + (-2 - 5)^2}\)
\(d = \sqrt {(1)^2 + (-7)^2}\)
\(d = \sqrt {{1} + {49}}\)
\(d = \sqrt {50}\)
\(d = 7.071068\)
Amanda is saving money to buy a game. The game costs $24 , and so far she has saved three-fourths of this cost. How much money has Amanda saved?
Answers
Answer:
18
Step-by-step explanation:
uuhhh I need some help
and the 4th answer is 2 1/2

Answers
Answer:
Simple answer, 2 1/2
Step-by-step explanation:
5/8 divided by 1/4 is 2.5. 2 and 1/2 means there is 2 whole units, and half a unit. Making it 2 and 1 half
A concave shaving mirror has a radius of curvature of +31.5 cm. It is positioned so that the (upright) image of a man's face is 3.40 times the size of the face. How far is the mirror from the face? Number i Units
Answers
The data includes a concave mirror with a radius of curvature of +31.5 cm and magnification of m = 3.40. The formula for magnification is m = v/u, and the focal length is f = r/2. Substituting the values, we get u = v/m, and using the mirror formula, the distance of the object from the mirror is 10.15 cm.
Given data: Radius of curvature of a concave mirror, r = +31.5 cm Magnification produced by the mirror, m = 3.40
We know that the formula for magnification is given by:
m = v/u where, v = the distance of the image from the mirror u = the distance of the object from the mirror We also know that the formula for the focal length of the mirror is given by :
f = r/2where,f = focal length of the mirror
Using the mirror formula:1/f = 1/v - 1/u
We know that a concave mirror has a positive focal length, so we can replace f with r/2.
We can now simplify the equation to get:1/(r/2) = 1/v - 1/u2/r = 1/v - 1/u
Also, from the given data, we have :m = v/u
Substituting the value of v/u in terms of m, we get: u/v = 1/m
So, u = v/m Substituting the value of u in terms of v/m in the previous equation, we get:2/r = 1/v - m/v Substituting the given values of r and m in the above equation, we get:2/31.5 = 1/v - 3.4/v Solving for v, we get: v = 22.6 cm Now that we know the distance of the image from the mirror, we can use the mirror formula to find the distance of the object from the mirror.1/f = 1/v - 1/u
Substituting the given values of r and v, we get:1/(31.5/2) = 1/22.6 - 1/u Solving for u, we get :u = 10.15 cm
Therefore, the distance of the mirror from the face is 10.15 cm. The units are centimeters (cm).Answer: 10.15 cm.
To know more about concave mirror Visit:
https://brainly.com/question/31379461
#SPJ11
URGENT!!!!
answer options:
cannot be determined
closer to point A
closer to point B
the same distance from both point a and b

Answers
Point M has the same distance from point A and point B (option d).
Given,
Line segment CD is the perpendicular bisector of line segment AB
AB ⊥ CD
Assume the conjecture that the set of points equidistant from A
and B is the perpendicular bisector of AB is true
Here, line segment CD intersect line segment AB at M
Then, M is the mid-point of line segment AB
So, the length of line AM = the length of line MB
That is, Point M has the same distance from both point A and point B.
Learn more about line segments here:
https://brainly.com/question/13207385
#SPJ1
Given: 5(x - 2) = 2x - 4 Prove:
What’s the The proof ?
Answers
Answer:
Step-by-step explanation:
its not right equation
because
5X - 10 ≠ 2X - 4
help me with pythagorean therom pleaseeeeeeeeeeeee i will legit do anything if someone can help i will give brainliest just help me pleaseeeeeeeeeeee

Answers
6.6,your answer is correct.
As the theorem is a^2+b^2=c^2 you first must assign the proper components to each variable. Since 12 is the longest since it is the hypotenuse that means it is c so in this case 144. And since 10 is the leg it is a.
To solve you must take
10^2+b^2=12^2
100+b=144
144-100=44
Since b^2 is 44 you must find the square root \(\sqrt{44}\)=6.6
Hey cuties, help me please I haven't had a lot of energy I've been fairly depressed so I'd appreciate it. You matter luvs, remember that!

Answers
Answer: -6?
Step-by-step explanation:
PLEASE HELP ME SOMEONE WITH THIS PLEASE SOMEEONE HELP ME ITS DUE TONIGHT PLEASEEE:(
Answers
The detail that best supports the inference that the auto manufacturing industry supports green solutions is -
"Pyrolysis generates low-cost energy that can be used in the automobile manufacturing industry".
What is Parabola?In mathematics, a parabola is a plane curve which is mirror-symmetrical and is approximately U-shaped.
Given is a graph as shown in the image attached.
We can write -
{ 1 } -
f{g(x)} = (x - 2)² - 2(x - 2) - 3
{ 2 } -
g{f(x)} = (x² - 2x - 3) - 2
Therefore, we can calculate f{g(x)} and g{f{x}) as -
f{g(x)} = (x - 2)² - 2(x - 2) - 3g{f(x)} = (x² - 2x - 3) - 2To solve more questions on Pyrolysis, visit the link -
brainly.com/question/30098550
#SPJ1

The solutions to 15(2a – 2) = 5(a2 – 1) are: a = 1, a = –1 a = 5, a = –1 a = 5, a = 1
Answers
The solution to the provided expression using the difference of square formula of algebra is a=1.
What is the difference of squares formula?The difference of square says, the difference of the square of two terms is equal to the product of their sum and difference. It can be given as,
a^2-b^2=(a+b)(a-b)
The given expression in the problem is,
\(15(2a - 2) = 5(a^2 -1)\)
From the property of difference of square, the above equation can be written as,
\(15(2a - 2) = 5[(a +1)(a-1)]\\15\times[2(a - 1)] = 5[(a +1)(a-1)]\)
Divide both side of the equation with (a-1) as,
\(5\times2 = 5(a +1)\)
Divide both side of the equation with number 5 as,
\(2 = (a +1)\\a=2-1\\a=1\)
Hence, the solution to the provided expression using the difference of square method of algebra is a=1.
Learn more about the difference of square here;
https://brainly.com/question/1148545
The solutions to 15(2a – 2) = 5(a2 – 1) are:
a = 1, a = –1
a = 5, a = –1
a = 5, a = 1
Answer:
C. a = 5, a = 1
Step-by-step explanation:
please help it would be reallyyyy nice tysmmwmsmssmm
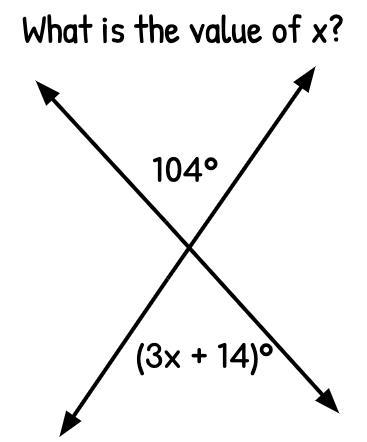
Answers
Answer:
I think it is 30
Step-by-step explanation:
Answer:
x = 30
Step-by-step explanation:
The angles shown are vertical angles
If you didn't know vertical angles are congruent
That being said we create an equation to solve for x
(because vertical angles are congruent) 104 = 3x + 14
now that we have created an equation we want to solve for x
Step 1 subtract 14 from each side
104 - 14 = 90
14 - 14 cancels out
now we have 90 = 3x
step 2 divide each side by 3
90/3=30
3x/3=x
we're left with x = 30
A professor counted the number of words students used to answer an essay question. Create a ranked frequency distribution of these data.
245 261 289 222 291 289 240 233 249 200
Answers
A ranked frequency distribution of data can be created by sorting the data in ascending or descending order and then counting the frequency of each value.
The given data set is 245, 261, 289, 222, 291, 289, 240, 233, 249, and 200. To create a ranked frequency distribution of this data set, we first need to sort it in ascending or descending order. Let's sort it in ascending order:200, 222, 233, 240, 245, 249, 261, 289, 289, 291 Next, we need to count the frequency of each value. We can do this by going through the data set and counting how many times each value occurs. Here is the frequency distribution table:Value Frequency 200 1222 1233 1240 1245 1249 1261 1289 2291 1 From this table, we can see that the most frequent value is 289, which occurs twice. We can also see that the least frequent values are 200, 222, 233, and 240, which each occur only once.
In conclusion, a ranked frequency distribution of data can be created by sorting the data in ascending or descending order and then counting the frequency of each value. This allows us to see which values are most and least frequent in the data set.
To know more about frequency distribution visit:
brainly.com/question/32535034
#SPJ11
The manager for a retail store must decide which sweaters to stock for the upcoming fall season. A sweater from one manufacturer comes in 5 different colors and in 3 different textures. The manager decides that the store will that the store will stock the sweater in 3 different colors and 2 different textures. How many different types of sweaters can the store choose to stock up on for the upcoming fall season?
Answers
The store can choose to stock up on 60 different types of sweaters for the upcoming fall season.
To determine the number of different types of sweaters the store can choose to stock up on, we need to calculate the total number of possible combinations of colors and textures
The store has 5 different colors and 3 different textures to choose from. Since they will stock the sweater in 3 different colors and 2 different textures, we can use the concept of combinations.
The number of combinations can be calculated using the formula:
C(n, r) = n! / (r!(n - r)!)
Where n represents the total number of options (colors or textures), and r represents the number of choices (colors or textures) the store will stock.
For colors:
n = 5 (total number of colors)
r = 3 (number of colors the store will stock).
C(5, 3) = 5! / (3!(5 - 3)!)
= 5! / (3!2!)
\(= (5 \times 4 \times 3!) / (3! \times 2 \times 1)\)
\(= (5 \times 4) / (2 \times 1)\)
= 10.
For textures:
n = 3 (total number of textures)
r = 2 (number of textures the store will stock)
C(3, 2) = 3! / (2!(3 - 2)!)
= 3! / (2!1!)
\(= (3 \times 2!) / (2! \times 1)\)
\(= (3 \times 2) / (1)\)
= 6
To calculate the total number of different types of sweaters, we multiply the number of color combinations by the number of texture combinations:
Total combinations\(= C(5, 3) \times C(3, 2)\)
\(= 10 \times 6\)
= 60
For similar question on combinations.
https://brainly.com/question/28065038
#SPJ11
What is the shortest time it takes it to collect a container of water?

Answers
Answer:
45 minutes
Step-by-step explanation:
The minimum of a box-and-whisker plot is the leftmost endpoint, called the "whisker". This minimum is the smallest value collected in the data.
What is the area of the figure?
A. 22 m2
B. 30 m2
O C. 33 m²
O D. 42 m2
E. 50 m2

Answers
Answer:
B. 30m2
Hope it helps you..