Use the drop-down menus to complete each equation so the statement about its solution is true.

Answers
Answer:
See below
Step-by-step explanation:
Equation given
2x + 9 + 3x + x = 6x + 9No solution ⇒ 6x + a, a≠9
Parallel lines, same slope and different y-interceptOne solution ⇒ ax + b, a≠6
Lines with different slopeInfinitely many solutions ⇒ a(6x + 9), a≠ 0
Overlapping linesRelated Questions
it takes 18 alan 18 minutes to type 14 pages of nites in histiry class. at this rate find out how long it takes him to type 77 pages, round answers to the nearest whole number.
Answers
Answer:
99 minutes if you divide 18 by 14 you will get time per page then multiply by 77 you will get 98.9 round it to 99
0.277 D Regression Statistics Multiple R R Square Adjusted R Square Standard Error Observations 0.038 1.552 100 ANOVA df F Significance F 1.976 0.104 4 Regression Residual Total SS 19.042 228.918 247.960 MS 4.760 2.410 95 99 Intercept X1 Coefficients Standard Error 7.505 1.213 0.147 0.057 -0.105 0.055 0.001 0.001 0.095 0.311 t Stat 6.187 2.594 -1.902 с 0.305 P-value 0.000 0.011 0.060 0.063 0.761 Lower 95% Upper 95% 5.097 9.913 0.034 0.259 A B 0.000 0.002 -0.523 0.713 X2 X3 X4 A statistician wants to investigate a phenomenon using multiple regression analysis. She uses four independent variables: X1, X2, X3, and X4, and her dependent variable is Y. To estimate the multiple regression model, she uses the ordinary least squares estimator. The estimation results are given in the output table below. Answer the following questions: 1. (4 points) Interpret the parameter estimate of X1. Explain. 2. (4 points) X4 is a dummy variable. How would you interpret the parameter estimate of X4? Explain. 3. (3 points) Which parameter estimates are statistically significant at 5% level of significance. Interpret. 4. (4 points) Calculate the 95% confidence interval of X2 (A=? and B=?). Use t-value = 1.96 in your calculations. Write down the formula and how you calculate them. Explain. 5. (3 points) Test the hypothesis that whether the overall model is statistically significant. Which test do you use? What is the decision? Explain. 6. (3 points) Calculate the value of t-statistics (C=?) for X3. Write down the formula and explain. 7. (5 points) Calculate and interpret the R-squared of the model (D=?). Discuss if the fit is good or not. Explain.
Answers
The parameter estimate of X1 is 0.147. It means that, holding all other variables constant, a unit increase in X1 is associated with a 0.147 increase in Y.
X4 is a dummy variable, which takes the value of 1 if a certain condition is met and 0 otherwise. The parameter estimate of X4 is -0.105, which means that, on average, the value of Y decreases by 0.105 units when X4 equals 1 (compared to when X4 equals 0).
The parameter estimates that are statistically significant at 5% level of significance are X1 and X2. This can be determined by looking at the p-values in the table. The p-value for X1 is less than 0.05, which means that the parameter estimate for X1 is statistically significant.
Similarly, the p-value for X2 is less than 0.05, which means that the parameter estimate for X2 is statistically significant.
The 95% confidence interval for X2 can be calculated using the formula:
B ± t-value * SE(B)
where B is the parameter estimate for X2, t-value is 1.96 (for a 95% confidence interval), and SE(B) is the standard error of the parameter estimate for X2. From the table, the parameter estimate for X2 is 0.001 and the standard error is 0.001. Thus, the 95% confidence interval is:
0.001 ± 1.96 * 0.001 = (-0.001, 0.003)
This means that we can be 95% confident that the true value of the parameter estimate for X2 falls between -0.001 and 0.003.
To test whether the overall model is statistically significant, we use the F-test. The null hypothesis is that all the regression coefficients are zero (i.e., there is no linear relationship between the independent variables and the dependent variable).
The alternative hypothesis is that at least one of the regression coefficients is non-zero (i.e., there is a linear relationship between the independent variables and the dependent variable).
From the ANOVA table in the output, the F-statistic is 1.976 and the p-value is 0.104. Since the p-value is greater than 0.05, we fail to reject the null hypothesis and conclude that there is not enough evidence to suggest that the overall model is statistically significant.
The t-statistic for X3 can be calculated using the formula:
t = (B - 0) / SE(B)
where B is the parameter estimate for X3, and SE(B) is the standard error of the parameter estimate for X3. From the table, the parameter estimate for X3 is 0.095 and the standard error is 0.311. Thus, the t-statistic is:
t = (0.095 - 0) / 0.311 = 0.306
The R-squared of the model is 0.038, which means that only 3.8% of the variation in the dependent variable (Y) can be explained by the independent variables (X1, X2, X3, X4). This suggests that the fit is not very good, and there may be other factors that are influencing Y that are not captured by the model.
However, it is important to note that a low R-squared does not necessarily mean that the model is not useful or informative. It just means that there is a lot of unexplained variation in Y.
To know more about null hypothesis refer here:
https://brainly.com/question/28920252
#SPJ11
Find the area of this rectangle please help!

Answers
I got 9 7/9 by using a calculator
-4×(-2)[2×(-6)+3×(2×6-4-4)]
Answers
\(\large{\underline {\underline {\frak {SolutioN:-}}}}\)
➝ -4 × (-2) [2 × (-6)+ 3×(2×6-4-4) ]
➝ -4 × (-2) [2 × (-6) + 3 × (12-4-4) ]
➝ -4 × (-2) [2 × (-6) + 3 × (12-8) ]
➝ -4 × (-2) [2 × (-6) + 3 × (4) ]
➝ -4 × (-2) [2 × (-6) + 12 ]
➝ -4 × (-2) [(-12) + 12 ]
➝ -4 × (-2) [0]
➝ -4 × 0
➝ 0
Answer:
-4*-2
Step-by-step explanation:
the multiple of both side is 4*2*,26+*32*--=6 44
The numbers 0.1, 12, 15 and 124 can all be classified as counting numbers?
Answers
Answer:
No
Step-by-step explanation:
Counting numbers are considered to be whole numbers greater than zero. Whole numbers are positive numbers without decimals or fractions, so 12, 15, and 124 can be classified as counting numbers, but not 0.1.
hope this helps!!!
What is the simplified value of the exponential expression 27 superscript one-third?39.
Answers
The simplified value of the expression "27 superscript one-third" is 3 , the correct option is (a) .
In the question ,
it is given that ,
the statement for the exponential expression is "27 superscript one-third" ,
which can be written in numbers as
= \(27^{\frac{1}{3} }\)
the number 27 can be expressed as product of number "3" ,
27 = 3 × 3 × 3 = 3³ ,
Substituting the value of 27 in the expression ,
we get ,
= \(3^{3\times \frac{1}{3} }\)
= 3¹ ....because 3 × (1/3) = 1
= 3
So , \(27^{\frac{1}{3} }\) = 3 .
Therefore , the simplified value is 3 .
The given question is incomplete ,the complete question is
What is the simplified value of the exponential expression 27 superscript one-third ?
(a) 3
(b) 9
(c) 2
(d) 18
Learn more about Expression here
https://brainly.com/question/4482908
#SPJ4
when plotting the calibration curve, what is on the x-axis and the y-axis, respectively?
Answers
whilst plotting the calibration curve, various concentrations and respective absorbance is at the x-axis and the y-axis, respectively
What are coordinates?A pair of numbers called coordinates are used to locate a point or a form in a two-dimensional plane. The x-coordinate and the y-coordinate are two numbers that define a point's location on a 2D plane.
calibrating curve:
A calibration curve, additionally called a well-known curve, is a fashionable technique for figuring out the awareness of a substance in an unknown pattern via way of means of evaluating the unknown to a fixed of well-known samples of recognized awareness.
A calibration curve is a linear graphical representation of standard solutions of varying concertation on the X-axis and their respective absorbance on the Y-axis.
Therefore, when plotting the calibration curve, varying concentrations and respective absorbance is on the x-axis and the y-axis, respectively
Learn more about coordinates here:
https://brainly.com/question/20282507
#SPJ1
Tyrone looked so sad that his mother felt bad.
Tomorrow was his birthday. She smiled to herself.
"Tyrone will be so surprised," she thought. "He has no
idea that we have a puppy waiting for him at Grandma's
house." Tyrone saw his mother smiling to herself and
wondered what she was thinking.
3. Underline the words in the passage that can help you
find the point of view.
4. Which characters' thoughts are in this passage?
Answers
Answer:
3. This would be third person view
4. Tyrone's mother and Tyrone himself
Step-by-step explanation:
3. Explanation: "Tyrone will be so surprised," she thought. "He has no
idea that we have a puppy waiting for him at Grandma's
house." This is third person view because it says "thought" and whilst it is her view point, Tyrone wondered to himself - Tyrone saw his mother smiling to herself and wondered what she was thinking.- therefore, causing it to be third person point of view.
Some of Amber's daily activities are listed here. Use these descriptions to select the word or symbol that correctly completes each sentence. • Amber spends 3/16 of each day doing homework. • Amber spends 0.25 of each day at school. • Amber spends 1/3 of each day sleeping. (A) 3/16 of a day 0.25 of a day (B) 0.25 of a day 1/3 of a day (C) Amber spends time doing homework than she does at school. (D) Amber spends time sleeping than she does at school.
Answers
Answer: (D) Amber spends time sleeping than she does at school.
Step-by-step explanation:
Given that :
• Amber spends 3/16 of each day doing homework.
• Amber spends 0.25 of each day at school.
• Amber spends 1/3 of each day sleeping.
Hence,
Amber spends 0.1875 of a day doing homework, which is (0.1875 * 24) = 4.5 hours
0.25 of each day at school ; (0.25 * 24) = 6 hours
1/3 of each day sleeping ; (1/3 * 24) = 8 hours
Time spent sleeping = 8 hours
Time spent in school = 6 hours
The left and right ends of the normal probability distribution extend indefinitely, never quite touching the horizontal axis. True False
Answers
It is false as the left and right ends of the normal probability distribution extend indefinitely, approaching but never touching the horizontal axis.
The statement is false because the left and right ends of the normal probability distribution do not extend indefinitely. In reality, the normal distribution is defined over the entire real number line, meaning it extends infinitely in both the positive and negative directions. However, as the values move further away from the mean (the center of the distribution), the probability density decreases. This means that although the distribution approaches but never touches the horizontal axis at its tails, the probability of observing values extremely far away from the mean becomes extremely low. Thus, while the distribution theoretically extends infinitely, the practical probability of observing values far from the mean decreases rapidly.
To know more about normal probability distribution,
https://brainly.com/question/33601330
#SPJ11
Help ima diehehdbehvd
Dont mind my answer i picked anything

Answers
Margin of error: two percentage points; confidence level 90%; from a prior study, p is estimated by the decimal equivalent of 38%
n=
Margin of error: 0.04; confidence level 90%, p and q unknown
n=
find the critical value z a/2 that corresponds to the given confidence level.
89%
A programmer plans to develop a new software system. In planning for the operating system that he will use, he needs to estimate the percentage of computers that use a new operating system. How many computers must be surveyed in order to be 99% confident that his estimate is in error by no more than five percentage points question mark s?
n=
Answers
To find the critical value for a 90% confidence level, we need to divide the remaining 10% of the distribution (in the tails) by 2, as we are looking for a two-tailed test. This gives us 0.05, which we can use to find the corresponding z-value using a z-table or calculator. The critical value z a/2 for a 90% confidence level is 1.645.
To determine the sample size needed to estimate the percentage of computers using a new operating system with a 99% confidence level and a 5% margin of error, we can use the formula \(n = (z^2 * p * q) / E^2\). Plugging in the values, we find that a sample size of 610 computers is needed.This sample size calculation ensures that there is a 99% chance that the true percentage of computers using the new operating system is within 5 percentage points of the estimated percentage. It also assumes that the prior estimate of 38% is accurate, and that the population proportion is roughly evenly split between those using the new operating system and those not using it.
It is important to note that the sample size calculation assumes a random and representative sample of computers. If the sample is not truly random or representative, the results may not be accurate. Additionally, the margin of error is affected by the sample size, so if a smaller sample is used, the margin of error will be larger.
Learn more about error here : https://brainly.com/question/30762919
#SPJ11
A student group sells 500 raffle tickets for $2 each. At the drawing the top prize will be
a gift certificate for $100. Second prize will be a $50 gift card and there will be five 3rd
prizes, each a $20 gift card. Do you expect to win or lose (on average)? How much?
Answers
Answer:
Step-by-step explanation:
if there are 500 tixets and 7 prizes (1 top prize+1 second prize+5 third prize) your chances of wining are 7/500=0.014 or 1.4% chance
with a 1.4% chance of win and a 98.6% chance to loose in average you can expect to loose.
Multiply:4x^3sqrt4x^2(2^3sqrt32x^2-x^3sqrt2x)
Answers
8x^5\left(32\sqrt{2}x^2-\sqrt{2}x^4\right)
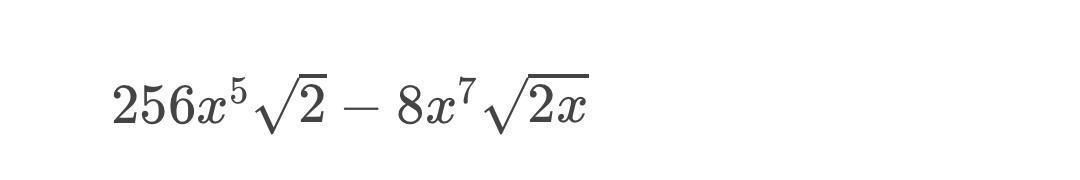
in a right skewed distribution the z score of the median is positive. give an example of right skewed data to illustrate your post (include the mean and the median).
Answers
Here is an example of right skewed data:
Data: 1, 1, 1, 1, 2, 2, 2, 3, 3, 4
Mean: 2.5
Median: 2
Z-score of median: 0.5
As you can see, the mean is greater than the median. This is because the data is right skewed, meaning that there are a few extreme values on the right side of the distribution that are pulling the mean up.
The z-score of the median is positive because the median is greater than the mean.
Another example of right skewed data is the distribution of income. In most countries, most people earn a modest amount of income, but there are a few people who earn a very high income. This creates a right skewed distribution, with the mean being greater than the median.
In a right skewed distribution, the z-score of the median is positive because the median is closer to the mean than the mode. The mode is the most frequent value in the distribution, and it is usually located on the left side of the distribution in a right skewed distribution.
The mean is pulled to the right by the extreme values, but the median is not affected as much because it is not as sensitive to extreme values.
Learn more about Right skewed distribution.
https://brainly.com/question/33316824
#SPJ11
It costs $24.00 for six tickets to the movies. How many tickets can you purchase with $64.00?
Answers
Answer:
12
Step-by-step explanation:
Martin was making play dough. He added 3/4 cup of flour to the bowl. Then he added another 3/8 cup. Is the total amount of flour he used greater or less then one cup
Answers
Answer:
It's greater then one cup
Step-by-step explanation:
Hope it helps :)
Have a good day/night
Brainliest pls?
Answer:
It is greater than 1 cup
Step-by-step explanation:
3/4 = 6/8
6/8 + 3/8 = 9/8
9/8 = 1 1/8
1 1/8 cups > 1 cups
does anyone else hate school right know
Answers
Yeah it literally sucks I can't concentrate because of the internet issues
Answer:
Yes! I hate this thing as well it ruined everything!!!!!!!
What does the intercept represent here

Answers
Answer:
the answer is that you need 2 quarters and no nickels to park for 60 minutes
The volume of the shape above is 4,000. The height is 10. What is the diameter for this cylinder prism?
Answers
Answer:
22.5
Step-by-step explanation:
the volume of a cylinder is πr2h
v=π*\(r^{2}\)*hwhich r =radius
Estimate the square root. Round to the nearest integer.
V56
Answers
So the square root is somewhere between 7 and 8
56 is 7 away from 49 and 8 away from 64 so we know the number will round to 7 but be fairly close to 7.5.
A good estimation would be 7.4
It’s asking you to round to the nearest integer (no decimals) so this would be 7
Because square roots are both positive and negative and it’s asking for it as an integer (includes negative numbers), the answers is +7 or -7. Both are the correct answer
What is the sum of the first 10 terms of the geometric series 2 + 6 + 18 + 54 + 162 + ...?
Answers
2 + 6 + 18 + 54 + ...
This is a geometric sum and there is a way to find the sum of however many terms as you would like.
The initial term is S1 = 2, the ratio of successive terms is r = 3.
The sum for a geometric sequence of the first n terms is given by
Sn = S1(1 - rn)/(1 - r)
Apply this formula for n = 10.
Jody made 5210 chocolates. Each box holds 28 chocolates. How many full boxes will she make, and how many chocolates will she have left?
Answers
Answer: 186 boxes, 2 left
Step-by-step explanation:
28x186=5,208
5,210-5,208=2
Find the angle x on the line. a triangle has 38 at the top and 101 on the outside of it.
Answers
Answer:
x=79°
Step-by-step explanation:
\(x + 101 = 180( < \: on \: str \: line = 180) \\ x = 180 - 101 \\ x = 79\)
What is the difference of the following polynomials? 6.x3-2x2+4 - (2.x3 + 4x2 - 5
Answers
Answer:
_84
Step-by-step explanation:
6.x3-2x2+4 - (2.x3 + 4x2 - 5)
18-4+4-2×3-4×2+5
18-4+2×(-1)×7
12×(-1)×7
84×(-1)
-84
look at screenshot
I really need help

Answers
Answer:
3rd option
Step-by-step explanation:
the equation of a line in point- slope form is
y - b = m(x - a)
where m is the slope and (a, b ) a point on the line
calculate m using the slope formula
m = \(\frac{y_{2}-y_{1} }{x_{2-x_{1} } }\)
with (x₁, y₁ ) = (- 4, - 1 ) and (x₂, y₂ ) = (5, 7 )
m = \(\frac{7-(-1)}{5-(-4)}\) = \(\frac{7+1}{5+4}\) = \(\frac{8}{9}\)
using (a, b ) = (- 4, - 1 ) then
y - (- 1) = \(\frac{8}{9}\) (x - (- 4) ) , that is
y + 1 = \(\frac{8}{9}\) (x + 4)
The line plot above shows the amount of sugar used in 12 different cupcake recipes.
Charlotte would like to try out each recipe. If she has 7 cups of sugar at home, will she have enough to make all 12 recipes?
If not, how many more cups of sugar will she need to buy?
Show your work and explain your reasoning.
Answers
From the given information, we don't have specific data about the sugar quantities for each recipe. Therefore, we cannot directly calculate the total amount of sugar needed for all 12 recipes.
However, we can determine an estimate or an average amount of sugar used per recipe based on the data presented in the line plot. We'll assume that the sugar quantities on the line plot represent the amounts used in the 12 recipes.
By summing up the sugar quantities on the line plot, we get:
3 + 2 + 4 + 3 + 2 + 3 + 2 + 3 + 3 + 4 + 2 + 3 = 34 cups
The total amount of sugar required for these 12 recipes is 34 cups.
Since Charlotte has 7 cups of sugar at home, we can compare this amount to the total amount needed. If 34 cups is greater than 7 cups, she does not have enough sugar to make all 12 recipes.
In this case, 34 > 7, so Charlotte does not have enough sugar to make all 12 recipes.
To determine how many more cups of sugar she needs to buy, we subtract the amount she has from the total amount required:
34 - 7 = 27 cups
Therefore, Charlotte would need to buy 27 more cups of sugar to have enough for all 12 recipes.
The radius of Circle A is 6 cm. The radius of Circle B is 2 cm greater than the radius of Circle A. The radius of Circle C is 3 cm greater than the radius of Circle B. The radius of Circle D is 2 cm less than the radius of Circle C. What is the area of each circle?
Answers
Answer:
circle a: 3.14x36= 113.04
circle b: 3.14 x 64 = 200.96
circle c: 3.14 x 121= 379.94
circle d : 3.14 x 81 = 254.34
Step-by-step explanation: circle a is 6cm, circle b is 8 cm, circle c is 11 cm and circle d is 9cm.
and (Area = π r²) example: circle a 6²=36 and π=3.14 so 3.14x36=113.04
the source, format, assumptions and constraints, and other facts concerning certain data are called .
Answers
The source, format, assumptions and constraints, and other facts concerning certain data are collectively called 'metadata'.
Metadata provides information about data that helps users understand and use it effectively.
Some examples of metadata include,
The date and time the data was collected.
The file format of the data.
The units of measurement used.
And any assumptions or limitations that were made during the collection or analysis of the data.
By providing metadata along with the data, users can better understand the context and quality of the data.
This can help them make more accurate and informed decisions.
Metadata is classified into three types which are known as descriptive, administrative, and structural.
learn more about data here
brainly.com/question/30168201
#SPJ4
If iq scores are normally distributed, having a mean of 100 and a standard deviation of 15, approximately what percentage of people have iq scores somewhere between 70 and 130?
Answers
The percentage of people have iq scores somewhere between 70 and 130 is 95.44%.
To solve this problem, we need to standardize the IQ scores and then use a standard normal distribution table or calculator to find the proportion of scores between 70 and 130.
First, we need to calculate the z-scores for IQ scores of 70 and 130, using the formula:
z = (x - μ) / σ
where x is the IQ score, μ is the mean (100), and σ is the standard deviation (15).
For an IQ score of 70:
z = (70 - 100) / 15 = -2
For an IQ score of 130:
z = (130 - 100) / 15 = 2
We can now look up the proportion of scores between -2 and 2 in a standard normal distribution table or calculator. This represents the proportion of scores within two standard deviations of the mean, which is approximately 95% according to the empirical rule of normal distribution.
However, we want to find the proportion of scores between 70 and 130, not between -2 and 2. To do this, we need to subtract the proportion of scores below 70 (which is the same as the proportion below -2) from the proportion of scores below 130 (which is the same as the proportion below 2). The result gives us the proportion of scores between 70 and 130.
Using a standard normal distribution table or calculator, we can find that the proportion of scores below -2 (or 70) is 0.0228, and the proportion of scores below 2 (or 130) is 0.9772. Therefore, the proportion of scores between 70 and 130 is:
0.9772 - 0.0228 = 0.9544
This means that approximately 95.44% of people have IQ scores between 70 and 130.
To learn more about percentage here:
https://brainly.com/question/14695543
#SPJ4