
Answers
Answer:
the answer is D because it does not have a function
Answer:
Hi!!!
Step-by-step explanation:
How was your day today? Was it going great?
Related Questions
2. What is the average salary offered to a Stony Brook college graduate? To study this question you and a friend interview N students that graduated last year, and ask them what they earn. Student i's response was recorded as Yi. You are interested in the average, My. You assumed that the sample of Y's is iid. First you calculate the following estimate of uy: W1 N 1 N i=1 ΣΥ. . You and your friend each collected half the data. Thus you collected Y1, ..., YN/2 and your friend collected Yn/2+1, ... , Yn. Unfortunately, it turns out that your friend collected the data at a wild alumnae party, and you suspect that these data may not be as precise as your data. So whereas the variance of your data is, var(Y;) = 0%, i = 1, ...,N/2. then your friends data have the variance, var(Y) = oʻ(1 + 3c), i=N/2+1, ...,N, for some constant c> 0. (d) Your friend is sorry that half the data are not as precise as they could have been, and suggest that you discard the noise data, and simply use hr Na Ex? Y; as your estimator for my. Which estimator is most efficient (has the smallest variance) în or îz? Does your answer depend on c? = N.Σ. (Υ – μ.) - = (e) Suppose now that c = 0 such that var(Y;) = o2 for i = 1, ...,N. You have N = 300 observation and calculate s2 = 20,000,000 and î1 = $48,000. Before collecting the data, your friend argues mean salary, my, is s $50,000, using a 1% significance level. Write down the confidence interval at 1% significance level and decide whether you will accept your friend's
Answers
The more precise estimator ẏ₁ is the most efficient in estimating the average salary. With given values, the confidence interval is calculated to determine whether to accept the claim of a $50,000 mean salary.
In this scenario, we have two estimators for the average salary: ẏ₁, which uses precise data, and ẏ₂, which includes less precise data. The efficiency of the estimators depends on the variance of the data. If we compare the variances, Var(ẏ₁) = 0% and Var(ẏ₂) = o²(1 + 3c). Since Var(ẏ₁) is zero, it implies that ẏ₁ is the most efficient estimator. The answer does not depend on the value of c.
In the second part, with c = 0, we have Var(Y) = o². Given N = 300, s² = 20,000,000, and ẏ₁ = $48,000, we can use these values to construct a confidence interval. Using a 1% significance level, the critical value is 2.57 (from the standard normal distribution). The confidence interval is given by ẏ₁ ± 2.57 * sqrt(s²/N), which results in $48,000 ± 2.57 * sqrt(20,000,000/300). If this interval contains $50,000, we would accept your friend's claim; otherwise, we would reject it.
To learn more about average click here
brainly.com/question/29550341
#SPJ11
How do you solve this?
72a^3b^4/6a^2b
Answers
The expression (72a³b⁴) / (6a²b) is equivalent to the expression 12ab³.
What is an equivalent?The equivalent is the expression that is in different forms but is equal to the same value.
The definition of simplicity is making something simpler to achieve or grasp while also making it a little less difficult.
The expression is given below.
⇒ (72a³b⁴) / (6a²b)
Simplify the expression, then we have
⇒ (72a³b⁴) / (6a²b)
⇒ 12ab³
The expression (72a³b⁴) / (6a²b) is equivalent to the expression 12ab³.
More about the equivalent link is given below.
https://brainly.com/question/889935
#SPJ9
5. Cardi B is buying packs of gum from the grocery store. The table shows the total cost of the gum based on the number of packs bought. Which of the following represents the constant of proportionality?
Answers
to define a default field value, add the attribute ____.
Answers
To define a default field value in a form or a database, you can use the attribute "default". When you add the "default" attribute to a field, it will automatically assign the specified value to that field if no other value is provided by the user or system.
This can be particularly useful when designing forms or databases that require certain fields to have a value even when the user does not provide one.
For example, in a web form, you might have a "Country" field that requires users to select their country from a dropdown list. By setting a default value for this field, such as "United States," the system ensures that there is always a value associated with that field even if the user does not make a selection.
Similarly, in a database schema, you might have a "DateCreated" field that automatically assigns the current date and time as the default value. This ensures that the date and time are always recorded for each new entry, even if the user does not manually input a value.
In both cases, the "default" attribute allows you to streamline the data collection process and ensure that your forms and databases maintain consistent and complete data. Using default values can also improve the user experience by reducing the amount of input required, making it easier for users to complete forms and submit their data.
To learn more about the database, refer:-
https://brainly.com/question/30634903
#SPJ11
An experiment is conducted with a bag of marbles containing 5 red and 2 blue marbles. The results of a marble being drawn twice and replaced 100 times are shown in the table. Outcome Frequency Red, Red 19 Red, Blue 32 Blue, Blue 21 Blue, Red 28 Find P(no blue). 5 over 100 19 over 100 25 over 100 75 over 100
Answers
The probability of not drawing a blue marble is 0.51, which can also be expressed as 51/100 or 51%.
To find the probability of not drawing a blue marble (P(no blue)), we need to consider the outcomes where blue marbles are not drawn.
From the given table, we can see that the outcomes are categorized as Red, Red; Red, Blue; Blue, Blue; and Blue, Red.
The outcomes "Red, Red" and "Red, Blue" are the ones where blue marbles are not drawn, as the first marble drawn is red in both cases.
The frequency of the outcome "Red, Red" is 19, and the frequency of the outcome "Red, Blue" is 32.
Adding these frequencies together gives us 19 + 32 = 51.
Since the experiment involves drawing marbles twice and replacing them, the total number of outcomes is 100.
Therefore, the probability of not drawing a blue marble (P(no blue)) can be calculated as the frequency of the desired outcomes (51) divided by the total number of outcomes (100):
P(no blue) = 51/100
Simplifying this fraction, we get:
P(no blue) = 0.51.
So, the probability of not drawing a blue marble is 0.51, which can also be expressed as 51/100 or 51%.
In conclusion, based on the given data, the probability of not drawing a blue marble in the experiment is 0.51 or 51%.
For similar question on probability.
https://brainly.com/question/7965468
#SPJ11
help me please
i attached a picture :(

Answers
The range of the function is -3 < y ≤ 5, the asymptote is y = -3 and the end behaviour of the graph is: as x ⇒ 2, f(x) ⇒ 5 and as x ⇒ -∝, f(x) ⇒ -3
The range of the functionGiven that we have the following function definitions
f(x) = 2ˣ ⁺ ¹ - 3 for x ≤ 2
f(x) = 10/x for x > 2
The maximum value of the function is
f(max) = 2² ⁺ ¹ - 3 or f(max) = 10/2
f(max) = 5 or f(max) = 10/2
The minimum is at the asymptote of
f(x) = 2ˣ ⁺ ¹ - 3 for x ≤ 2
So, we have
f(min) = -3
This means that
Range: -3 < y ≤ 5
The asymptoteIn (a), we have
f(min) = -3
This means that
Asymptote: y = -3
The end behaviour of the graphThe graph would approach the maximum as x approaches the hole i.e. x = 2 and the graph would approach the asymptote as x approaches negative infinity
So, the end behaviour of the graph is: as x ⇒ 2, f(x) ⇒ 5 and as x ⇒ -∝, f(x) ⇒ -3
Read more about functions at
https://brainly.com/question/4138300
#SPJ1
There are only green yellow blue cubes in a bag
Answers
Answer:
1 ÷ 11
Step-by-step explanation:
The computation is shown below:
let us assume the yellow cubes be x
So, blue cubes be 2x
And, green cubes be 2x (4) 8x
Now the ratio is
Yellow: Blue: green
x:2x:8x
1:2:8
Now the probability of yellow cubes is
= 1 ÷ (1 + 2 + 8)
= 1 ÷ 11
SOMEONE HELPPPP PLS!!!?

Answers
Answer:
1
Step-by-step explanation:
:)
Answer:
1
Step-by-step explanation:
3(2x+1)=9 *multiply 3 to 2x and 1*
6x + 3 = 9 *subtract 3 from both sides*
6x = 6 *divide each side by 6
x=1
Which of the following is not a phase in the planning of both statistical and non-statistical sampling?
A) Plan the sample.
B) Determine the probability that fraud has occurred.
C) Select the sample and perform the tests.
D) Evaluate the results
Answers
The phase that is not a part of the planning process for both statistical and non-statistical sampling is determining the sample size.
What aspect is excluded from planning both statistical and non-statistical sampling?Determining the sample size is an essential step in statistical sampling, as it involves calculating the number of observations needed to ensure statistical validity. However, in non-statistical sampling, the focus is on selecting specific cases or items for examination based on subjective criteria, rather than relying on statistical principles or sample size calculations. Instead, non-statistical sampling emphasizes judgment and expert knowledge to choose representative samples. By excluding the determination of sample size, non-statistical sampling allows for greater flexibility and adaptability in the sampling process, enabling a more tailored approach to the specific objectives of the study or investigation.
Learn more about Statistical
brainly.com/question/29825986
#SPJ11
1. A line has a slope of 6 and includes the
points (-1, q) and (0, -7). What is the
value of q?
Answers
Answer:
q = - 13
Step-by-step explanation:
Calculate the slope m using the slope formula and equate to 6
m = \(\frac{y_{2}-y_{1} }{x_{2}-x_{1} }\)
with (x₁, y₁ ) = (- 1, q) and (x₂, y₂ ) = (0, - 7)
m = \(\frac{-7-q}{0+1}\) = - 7 - q , then
- 7 - q = 6 ( add 7 to both sides )
- q = 13 ( multiply both sides by - 1 )
q = - 13
Answer:
q = -13?
Step-by-step explanation:
the equation is y = mx + c
m is the gradient
c is the y-intercept
where the line crosses the y axis
If 6 is the gradient then the equation is
y = 6x + c
Find c by using the coordinates given:
-7 = ( 6× 0) +c
-7 = 0 + c
c = -7
the equation is y = 6x -7
Substitute the other coordinates to find q:
y or q = (6 ×-1) - 7
q = -6 -7
q = -13
ln((1+x)/(1-x)) power series
Answers
This is the power series representation for the function ln((1+x)/(1-x)). Note that the series converges for |x| < 1.
The power series representation for the function ln((1+x)/(1-x)) can be found using Taylor series expansion. First, we need to express the given function in a form suitable for Taylor series expansion.
The Taylor series expansion is a way to represent a function as an infinite series of terms involving powers of the variable centered around a specific point x = a. It is a generalization of the Maclaurin series expansion, which is a special case of the Taylor series when the expansion is centered around x = 0.
The Taylor series expansion of a function f(x) centered at x = a is given by:
f(x) = f(a) + f'(a)(x - a) + f''(a)((x - a)^2/2!) + f'''(a)((x - a)^3/3!) + ...
where f(a) represents the value of the function at x = a, f'(a) represents the derivative of the function evaluated at x = a, f''(a) represents the second derivative evaluated at x = a, and so on. The terms involving higher derivatives are divided by the corresponding factorial to account for the decreasing influence of higher powers of (x - a).
To do this, we can use the following identity:
ln(1+y) = y - y^2/2 + y^3/3 - y^4/4 + ... (where |y| < 1)
In our case, y = (2x)/(1-x), so:
ln((1+x)/(1-x)) = ln(1 + (2x)/(1-x))
Now, applying the identity and substituting y with (2x)/(1-x):
ln((1+x)/(1-x)) = (2x)/(1-x) - ((2x)/(1-x))^2/2 + ((2x)/(1-x))^3/3 - ...
To know more about Taylor series expansion, visit:
https://brainly.com/question/31657497
#SPJ11
In ASTU, u = 280 inches, 2T=63° and ZU=29º. Find the length of t, to the nearest
10th of an inch.
Answers
Answer:
514.6
Step-by-step explanation:
The robotics club is selling shirts for a fundraiser. They have purchased a box of shirts for $400 at $5 per shirt. To promote their fundraiser, they have also spent $60 on advertising.
Answers
Answer:
80x-460=300
80x=760
Step-by-step explanation:
In order to know which equation is best, you have to add the total expenses the robotics club had.
Expenses:
box of shirts = $400advertising = $60Let's add: $400 + $60 = $460
Next, you have to know how many of the shirts were purchased.
$400 ÷ $5 = 80Now, let's compute.
80x - 460 = 30080x = 300 + 46080x = 760x = $9.5or
80x=760x = 760 ÷ 80x = $9.5This means that the robotics club has to sell the shirts at $9.5 each in order to have a $300 profit.
Find the product of (-1-3i) and its conjugateProduct=
Answers
Explanation
To find the complex conjugate of -1-3i we change the sign of the imaginary part. Therefore, the conjugate is -1+3i
We can then find the product of -1-3i and its conjugate -1+3i below.
\(\begin{gathered} \mathrm{Apply\:complex\:arithmetic\:rule}:\quad \left(a+bi\right)\left(a-bi\right)=a^2+b^2 \\ a=-1,\:b=-3 \\ =\left(-1\right)^2+\left(-3\right)^2 \\ =1+9 \\ =10 \end{gathered}\)Answer: 10
In ΔQRS, the measure of ∠S=90°, the measure of ∠R=18°, and RS = 25 feet. Find the length of QR (to the nearest 10th of a foot).
Answers
In triangle ΔQRS, with ∠S = 90° and ∠R = 18°, and given that RS = 25 feet, we need to find the length of QR.
To find the length of QR, we can use trigonometric ratios based on the given angles in the right triangle ΔQRS. Since ∠S = 90°, we know that QR is the hypotenuse of the triangle. Let's denote the length of QR as x.
Using the sine ratio, we can write:
sin(∠R) = opposite/hypotenuse
sin(18°) = RS/QR
sin(18°) = 25/x
To solve for x, we can rearrange the equation: x = 25 / sin(18°)
By substituting the value of sin(18°) into the equation and evaluating it, we can find the approximate length of QR.
Calculating the value, we get: x ≈ 79.68 feet (rounded to the nearest 10th of a foot).Therefore, the length of QR is approximately 79.68 feet when rounded to the nearest 10th of a foot.
Learn more about length here:
https://brainly.com/question/24273594
#SPJ11
In an experiment, the factor that we measure is called the:A. conclusionB. independent variableC. controlled variableD. dependent variable
Answers
Option d. dependent variable. In an experiment, the dependent variable is the factor that is being measured or observed.
It is the variable that is expected to change or be affected as a result of the manipulation of the independent variable. The independent variable is the factor that is being manipulated or controlled in the experiment, while the controlled variable is a factor that is kept constant or consistent throughout the experiment to prevent it from affecting the dependent variable. The dependent variable is often used to draw conclusions about the relationship between the independent variable and the outcome of the experiment.
Learn more about mathematics here: brainly.com/question/24600056
#SPJ4
while logistic regression and classification and regression trees (cart) have the same end goal, each model approaches the goal in a different way. discuss the differences in the two models. provide a specific example of a situation where employing a cart model would be preferable to a logistic regression model. explain what makes the cart model superior in your example.
Answers
Logistic regression models the probability of a binary outcome, while CART models segment data into categories. For example, CART is preferable when data has complex interactions, as it can partition data into multiple categories.
Logistic regression and classification and regression trees (CART) are two different machine learning models used for binary classification problems. Logistic regression models the probability of one class or the other based on a linear combination of input variables. This makes it useful for predicting a binary outcome, such as whether a customer will purchase a product or not. On the other hand, CART is a decision tree model that divides data into categories. It uses a tree-like structure to split the data into segments based on the input features. This makes it useful for dealing with data with complex interactions, as it can partition data into multiple categories. For example, a CART model would be preferable to a logistic regression model if there are multiple underlying factors that affect the binary outcome. In this case, a CART model could more accurately identify the categories that are associated with a particular outcome. Overall, CART models are superior for dealing with data with complex interactions, whereas logistic regression is better for simpler data.
Learn more about probability here
https://brainly.com/question/11234923
#SPJ4
A new car is purchased for 24300 dollars. The value of the car depreciates at 15% per year. To the nearest year, how long will it be until the value of the car is 5600 dollars?
Answers
Answer:
9 years
Step-by-step explanation:
Losing 15 % means 85% remains
so multiply each year's value by .85 to find the current value
after 'n' years it will be 24300 * .85^n
when will it be 5600 ?
5600 = 24300 * .85^n
5600/24300 = .85^n
now you need to take the log of both sides and solve for 'n' years
log ( 5600/24300) / log(.85) = n = 9.031 = ~~ 9 years
Kevin is painting a border around his dining room. What measurement does Kevin need to know about the wall before he starts?
1: Area
2: Volume
3:Perimeter
Answers
Answer:
Perimeter
Step-by-step explanation:
Perimeter is the distance around an object. In this scenario the object in question would be Kevin's dining room. Keyword for perimeter here is around.
This is because Perimeter is the amount around the space and everything
what are the two assumptions that must be met in order to construct a confidence interval for (population mean) when (population standard deviation) is known?
Answers
In order to construct a confidence interval for the population mean when the population standard deviation is known, two assumptions must be met. Firstly, the sample data must be a simple random sample from the population being studied.
Secondly, the variable being measured must have a normal distribution or the sample size must be sufficiently large. The first assumption of a simple random sample ensures that the sample is representative of the population being studied, which is necessary for valid statistical inference. The second assumption is necessary because the confidence interval calculation relies on the assumption that the sample mean follows a normal distribution. When the variable being measured has a normal distribution, the sample mean will also have a normal distribution regardless of the sample size. When the variable being measured does not have a normal distribution, the sample size must be large enough (typically at least 30) in order for the sample mean to follow a normal distribution due to the central limit theorem. By meeting these two assumptions, we can be confident in the accuracy of the resulting confidence interval for the population mean.
Learn more about normal distribution here: brainly.com/question/31493997
#SPJ11
A password contains 6 digits such as 174668 how many different passwords can be formed
Answers
Answer:
there are 1 million possible passwords
Answer: One million possible combinations
i need help with the answers

Answers
Answer:
1.A
2.C
3.D
4.B
5.C
6.A
please help will give brainistFor two programs that total 1073 students, the type of student for two majors is as follows. Undergraduate Graduate History Science 390 422 73 188 Find the probability a student is a science major, given they are a graduate student. P(AnB) P(B|A) = P(A) P(science | graduate) = [?] Round to the nearest hundredth. I Enter

Answers
The probability that a student is a science major, given they are a graduate student is given as follows:
P(science|graduate) = 0.7203 = 72.03%.
How to calculate a probability?A probability is calculated as the division of the desired number of outcomes by the total number of outcomes in the context of a problem/experiment.
The outcomes for this problem are given as follows:
Desired outcomes: graduate science students -> 188 from the table.Total outcomes: graduate students: 73 + 188 = 261 students.Hence the probability that a student is a science major, given they are a graduate student is obtained as follows:
P(science|graduate) = 188/261
P(science|graduate) = 0.7203 = 72.03%.
More can be learned about probability at https://brainly.com/question/24756209
#SPJ1
Answer:
0.72
Step-by-step explanation:
What is the surface area of the figure?

Answers
Answer:
14
Step-by-step explanation:
5. the academy of orthopedic surgeons states that 80% of women wear shoes that are too small for their feet. a researcher wants to be 98% confident that this proportion is within 3 percentage points of the true proportion. how large of a sample is necessary? round to the nearest whole number. (10 points
Answers
To determine the sample size necessary for this study, we use the formula: n = (Z^2 * p * q) / E^2. The necessary sample size is approximately 1091.
Where:
- n = sample size
- Z = Z-score for the desired confidence level (98% confidence level corresponds to a Z-score of 2.33)
- p = estimated proportion (based on the information given, p = 0.8)
- q = 1 - p
- E = desired margin of error (3 percentage points)
Plugging in the values:
n = (2.33^2 * 0.8 * 0.2) / 0.03^2
n = 806.67
Rounding up to the nearest whole number, we get a sample size of 807. Therefore, the researcher needs to survey at least 807 women to be 98% confident that the proportion of women who wear shoes that are too small is within 3 percentage points of the true proportion.
To determine the necessary sample size for this study, we can use the formula for sample size calculation in proportion estimation:
n = (Z^2 * p * q) / E^2
where n is the sample size, Z is the Z-score corresponding to the desired confidence level, p is the estimated proportion, q is the complement of the proportion (1 - p), and E is the margin of error.
In this case, we have:
- Confidence level: 98%, which corresponds to a Z-score of 2.33 (from the standard normal distribution table)
- Estimated proportion (p): 80% or 0.80
- Complement of the proportion (q): 1 - 0.80 = 0.20
- Margin of error (E): 3 percentage points or 0.03
Now, we can plug these values into the formula:
n = (2.33^2 * 0.80 * 0.20) / 0.03^2
n ≈ 1090.65
Since we need to round to the nearest whole number, the necessary sample size is approximately 1091.
Learn more about Z-score at: brainly.com/question/31871890
#SPJ11
a rectangle is divided into 4 equal rows. there are 4 squares in each row. Leah says 1 square is 1/4 of the whole rectangle. is Leah correct
Answers
Answer: Yes Leah Is Correct.
Step-by-step explanation: Leah is correct because if you have a rectangle divided into 4 parts than if you will be asked how much parts will you need to make this fraction a whole you’ll say 4 since if you say for example six you will be wrong since six is too much so if you shade one part in than it’s 1/4 ths now let’s say you shaded in 3/4th you will see 3 shaded and one more left not shaded in which gives the fraction the name 3/4.
hope this made sense.
4x – 3y = -7
5x – 4y = - 8
Answers
The answer is x=−4 and y=−3
help for brainliest plsssssssssssssss

Answers
Answer:
There will be 416 students in each group.
Step-by-step explanation:
There are 1,248 students. There are also 3 groups: radical readers, mathematicians, and super scientists. To find the number of people in each group, divide the total students by the number groups, which would be 1,248 divided by 3.
answer : 416
Find the area of each segment to the nearest hundredth
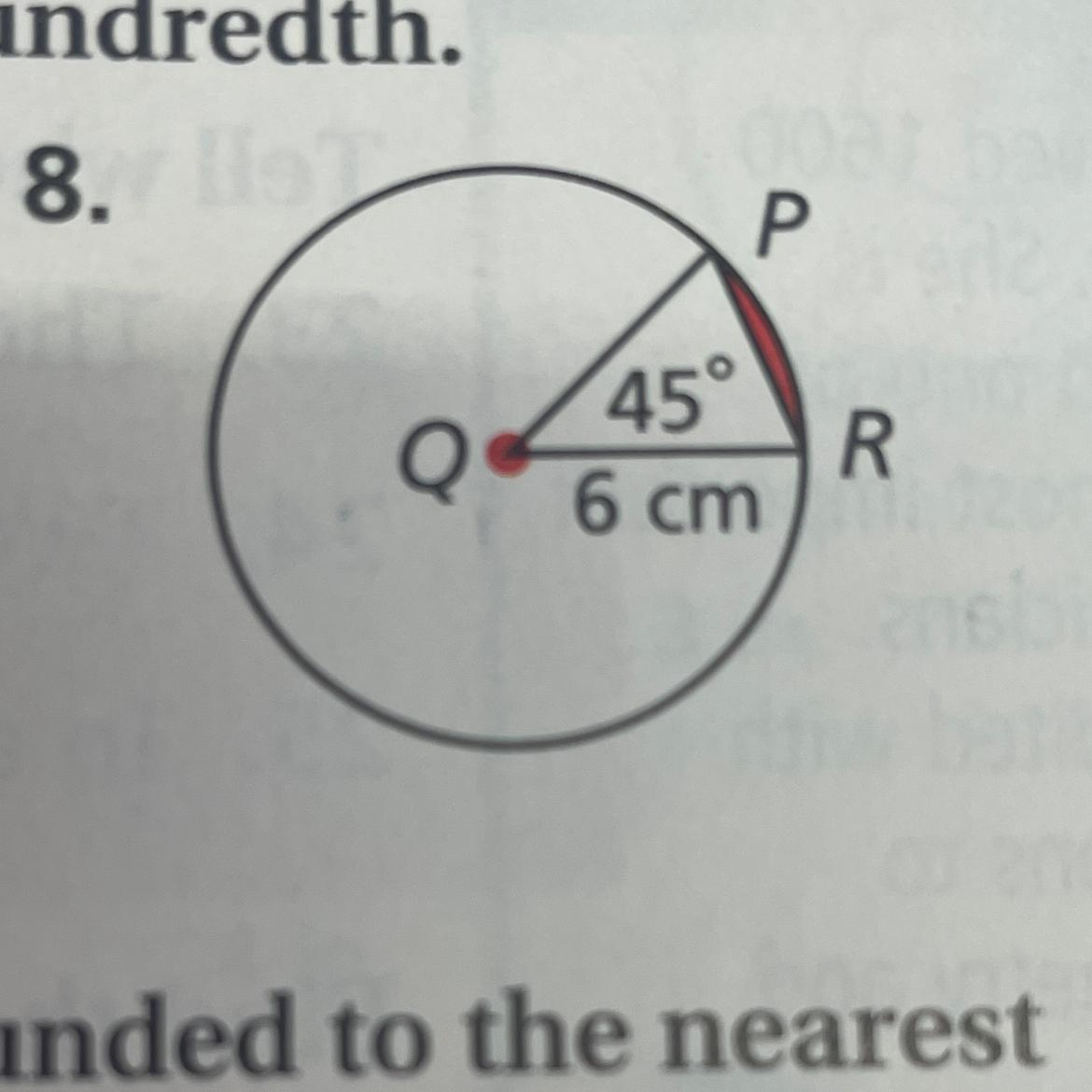
Answers
The area of the segment of the circle is 13.9cm²
What is the area of the segmentTo calculate the area of segment of the circle, we can use the formula which is given as;
A = (1/2) * r² * [(π/180)θ - sinθ]
In the problem, our data given are;
r = 6cmθ = 45°Substituting the values into the formula;
A = (1/2) * 6² * [(π/180)45 - sin45]
A = 0.5 * 36 * [(3.14/180)45 - sin45]
A = 0.5 * 36 * 0.773
A = 13.9cm²
The segment area is 13.9 squared meters
Learn more on area of segment here;
https://brainly.com/question/22599425
#SPJ1
NEED HELP ASAP!!!!! WILL GIVE BRAINLIEST!!
2+2
Answers
Answer:
2+2=4
Step-by-step explanation:
You've got this man.
Answer:
4
Step-by-step explanation: