Order these integers from least to greatest.
|-6|, |-3|, |0|, |9|, |-2|, |-15|
Answers
-6
-3
-2
0
9
hopefully this is right...
Related Questions
carla has a shirt with decorative pins in the shape of equilateral triang the pins come in two sizes. the larger pin has a side length that is three times longer than the smaller pin. if the area of the smaller pin is 6.9 square centimeters, what is the approximate area of the larger pin? round your answer to the nearest tenth.
Answers
The approximate area of the larger pin is :
62.1 square centimeters
To find the approximate area of the larger pin, we need to consider that the larger pin has a side length three times longer than the smaller pin, and we are given the area of the smaller pin as 6.9 square centimeters.
Identify that both pins are equilateral triangles.
Calculate the ratio of their side lengths (larger pin to smaller pin), which is 3:1.
Recall the formula for the area of an equilateral triangle: area = (side² * √3) / 4.
Since the ratio of side lengths is 3:1, the ratio of their areas is the square of the ratio of their side lengths (9:1).
Now, we can find the area of the larger pin using the area ratio:
If the area of the smaller pin is 6.9 square centimeters, the area of the larger pin is 9 times the area of the smaller pin (9 * 6.9 = 62.1 square centimeters).
Therefore, the approximate area of the larger pin is 62.1 square centimeters, rounded to the nearest tenth.
To learn more about area visit : https://brainly.com/question/25292087
#SPJ11
2,229-1,987 Subtract
Answers
242 is the answer
Answer:242
Step-by-step explanation:
If vector u= (-4,8) and vector (5,-18), which vector can be added to 2u-4v to give the unit vector in the direction of the y-axis as the resultant vector?
A. w = (12, -87)
B. w = (28, -55)
C. w = (28, -87)
D. w = (12, -55)
Answers
Answer:
hey buddy im gona help you!
Step-by-step explanation:

please help me im begging you

Answers
Answer:
9x + 14
Step-by-step explanation:
You need to add like terms. Add your x's together and your constants together:
5x + 4x + 6 + 8
9x + 14
Answer:
9x+14
Step-by-step explanation:
When you simplify the 5x+4x because they are like terms you just at them together. And 8+6 is 14 so you equation becomes 9x+14. You can't take it any farther than that.
Consider the function below. (If an answer does not exist, enter DNE.) f(x) = 1/2 x^4 - 4x^2 + 2 (a) Find the interval of increase. (Enter your answer using interval notation.) Find the interval of decrease. (Enter your answer using interval notation.) (b) Find the local minimum value(s). (Enter your answers as a comma-separated list.) Find the local maximum value(s). (Enter your answers as a comma-separated list.) (c) Find the inflection points. Find the interval where the graph is concave upward. (Enter your answer using interval notation.) Find the interval where the graph is concave downward. (Enter your answer using interval notation.)
Answers
the interval where the graph is concave upward is (2/√3, ∞) and the interval where the graph is concave downward is(∞-2/√3).
The given function is f(x) = 1/2 x^4 - 4x^2 + 2.(a) To find the interval of increase, we need to find the values of x for which the function is increasing.To find the interval of decrease, we need to find the values of x for which the function is decreasing.We know that if f'(x) > 0, then the function is increasing in that interval. Similarly, if f'(x) < 0, then the function is decreasing in that interval.f'(x) = 2x³ - 8x= 2x(x² - 4)= 2x(x - 2)(x + 2)Critical points occur where f'(x) = 0, or where the derivative does not exist.f'(x) = 0 when 2x(x - 2)(x + 2) = 02x = 0 (x - 2)(x + 2) = 0x = 0, ±2The critical points are x = 0, ±2. We can use these critical points to determine the intervals of increase and decrease of the function.Using the first derivative test, we find that:On the interval (-∞, -2), f'(x) < 0, so f(x) is decreasing.On the interval (-2, 0), f'(x) > 0, so f(x) is increasing.On the interval (0, 2), f'(x) < 0, so f(x) is decreasing.On the interval (2, ∞), f'(x) > 0, so f(x) is increasing.Therefore, the interval of increase is (−2, 0) U (2, ∞) and the interval of decrease is (−∞, −2) U (0, 2).(b) To find the local minimums and maximums, we need to find the critical points of the function and then determine whether they correspond to a local minimum or maximum.To do this, we need to use the second derivative test. If f''(x) > 0, then the function has a local minimum at that point. If f''(x) < 0, then the function has a local maximum at that point.f''(x) = 6x² - 8f''(0) = -8 < 0, so f(x) has a local maximum at x = 0.f''(-2) = 20 > 0, so f(x) has a local minimum at x = -2.f''(2) = 20 > 0, so f(x) has a local minimum at x = 2.Therefore, the local maximum is at x = 0, and the local minimums are at x = -2 and x = 2.(c) To find the inflection points, we need to find where the concavity of the function changes. This occurs where the second derivative is zero or undefined.f''(x) = 6x² - 8= 2(3x² - 4)We need to find where 3x² - 4 = 0.3x² = 4x = ±2/√3The inflection points are at x = -2/√3 and x = 2/√3.To find the intervals where the function is concave upward or downward, we need to determine the sign of the second derivative.f''(x) > 0, the function is concave upward.f''(x) < 0, the function is concave downward.f''(-2/√3) = 2(3(-2/√3)² - 4) < 0, so the function is concave downward on the interval (-∞, -2/√3).f''(2/√3) = 2(3(2/√3)² - 4) > 0, so the function is concave upward on the interval (2/√3, ∞).
To know more about this, derivative visit
https://brainly.com/question/29144258
#SPJ11
Maay I please get some help?

Answers
The complementary angle is 19 degrees and the supplementary angle is 109 degrees.
What are complementary angles?Complementary angles can be defined as the angles whose sum is 90 degrees.
The ‘c’ in complementary angle can be used to form 9 in 90 degrees. Supplementary angles are angles whose sum is 180 degrees. The ‘s’ in supplementary angle can be used to form 8 in 180 degrees
If the intersection of P and Q creates a 71 degree angle,
then 90 – 71 = 19 degrees is its complementary angle. Its supplementary angle is 180 – 71 = 109 degrees.
Therefore, The complementary angle is 19 degrees and the supplementary angle is 109 degrees.
So, The answer is D)
The complementary angle is 19 degrees and the supplementary angle is 109 degrees.
To learn more about Complementary angles from given link.
brainly.com/question/15592900
#SPJ1
Which graph represents y=⌈x⌉over the domain 2≤x≤5 ?

Answers
Answer:
4
Step-by-step explanation:
#1 has to be excluded, since it jumps from 4 to 5 and has a hole between x=4 and x=5
#2 loses the extreme values. It would be correct if the domain was \(2<x<5\)
#3 is including values in the interval \(1<x \leq 2\) which aren't in our domain.
#4 is the remaining one.
You may need to use the appropriate technology to answer this question.
The Consumer Reports Restaurant Customer Satisfaction Survey is based upon 148,599 visits to full-service restaurant chains. † One of the variables in the study is meal price, the average amount paid per person for dinner and drinks, minus the tip. Suppose a reporter for a local newspaper thought that it would be of interest to her readers to conduct a similar study for restaurants located in her city. The reporter selected a sample of 8 seafood restaurants, 8 Italian restaurants, and 8 steakhouses. The following data show the meal prices ($) obtained for the 24 restaurants sampled.
Italian Seafood Steakhouse
$12 $17 $23
13 18 18
16 18 24
16 27 25
18 23 21
19 15 23
18 20 28
24 14 30
Use α = 0. 05 to test whether there is a significant difference among the mean meal price for the three types of restaurants.
State the null and alternative hypotheses.
H0: μItalian = μSeafood = μSteakhouse
Ha: Not all the population means are equal.
H0: μItalian ≠ μSeafood ≠ μSteakhouse
Ha: μItalian = μSeafood = μSteakhouse
H0: At least two of the population means are equal.
Ha: At least two of the population means are different.
H0: Not all the population means are equal.
Ha: μItalian = μSeafood = μSteakhouse
H0: μItalian = μSeafood = μSteakhouse
Ha: μItalian ≠ μSeafood ≠ μSteakhouse
Find the value of the test statistic. (Round your answer to two decimal places. )
test statistic=
Find the p-value. (Round your answer to four decimal places. )
p-value =
What is your conclusion?
Do not reject H0. There is not sufficient evidence to conclude that the mean meal prices are not all the same for the three types of restaurants.
Reject H0. There is sufficient evidence to conclude that the mean meal prices are not all the same for the three types of restaurants.
Do not reject H0. There is sufficient evidence to conclude that the mean meal prices are not all the same for the three types of restaurants.
Reject H0. There is not sufficient evidence to conclude that the mean meal prices are not all the same for the three types of restaurants
Answers
A) The stated the null and alternative hypotheses are defined as
H₀ : μItalian = μSeafood = μsteakhouse
Hₐ : Not all the population means are equal. So, correct answer is option (a).
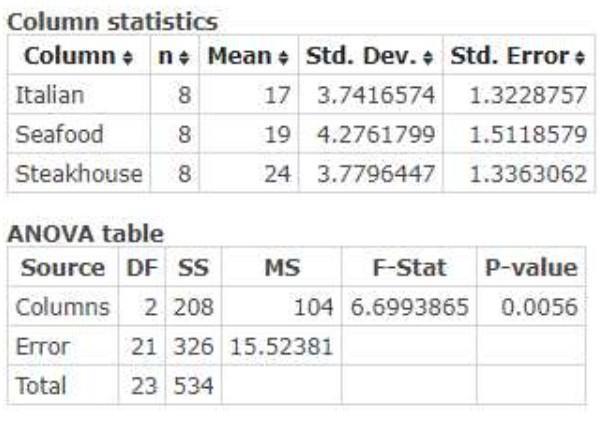
B) The value of the test statistic is equals to the 6.70. The p-value is equals to the 0.0056.
C) Conclusion : The null hypothesis H0 is rejected, so there is sufficient evidence to conclude that the mean meal prices are not all the same for the three types of restaurants.
We have a consumer reports Restaurant Customer Satisfaction Survey is based upon 148,599 visits to full-service restaurant chains. The above table data show the meal prices ($) obtained for the 24 restaurants sampled ( 8 seafood restaurants, 8 Italian restaurants, and 8 steakhouses). So, sample size , n = 24
Significance level = 0.05
A) For Hypothesis testing, the null and alternative hypothesis are defined as
H₀ : μItalian = μSeafood = μsteakhouse
Hₐ : Not all the population means are equal. So, correct answer is option (a).
B) We have more than two groups for analysis so we use ANOVA test to compare the means among three or more groups. Using the Excel the above second table is made which represents the mean, standard deviations and standard error for data. It also contains ANOVA table. So,
Mean value of Italian = 17
Mean value of Seafood = 19
Mean value of steakhouse = 24
Uding all the above details or Excel command, The value of the F test- statistic value = 6.70
Using the distribution table, the p-value for test-static value 6.70 is 0.0056.
C)Now, we see P-value = 0.0056 < 0.05, which implies the null hypothesis is rejected. Thus, There is sufficient evidence to conclude that the mean meal prices are not all the same for the three types of restaurants.
For more information about null hypothesis, visit :
https://brainly.com/question/25263462
#SPJ4
Complete question:
You may need to use the appropriate technology to answer this question. The Consumer Reports Restaurant Customer Satisfaction Survey is based upon 148,599 visits to full-service restaurant chains. † One of the variables in the study is meal price, the average amount paid per person for dinner and drinks, minus the tip. Suppose a reporter for a local newspaper thought that it would be of interest to her readers to conduct a similar study for restaurants located in her city. The reporter selected a sample of 8 seafood restaurants, 8 Italian restaurants, and 8 steakhouses. The following data show the meal prices ($) obtained for the 24 restaurants sampled.
Italian Seafood Steakhouse
$12 $17 $23
13 18 18
16 18 24
16 27 25
18 23 21
19 15 23
18 20 28
24 14 30
Use α = 0. 05 to test whether there is a significant difference among the mean meal price for the three types of restaurants. State the null and alternative hypotheses.
a) H0: μItalian = μSeafood = μSteakhouse
Ha: Not all the population means are equal.
b)H0: μItalian ≠ μSeafood ≠ μSteakhouse
Ha: μItalian = μSeafood = μSteakhouse
c) H0: At least two of the population means are equal.
Ha: At least two of the population means are different.
d)H0: Not all the population means are equal.
Ha: μItalian = μSeafood = μSteakhouse
e) H0: μItalian = μSeafood = μSteakhouse
Ha: μItalian ≠ μSeafood ≠ μSteakhouse
B) Find the value of the test statistic. (Round your answer to two decimal places. )
test statistic=___
Find the p-value. (Round your answer to four decimal places. )p-value =____
V)What is your conclusion?
a)Do not reject H0. There is not sufficient evidence to conclude that the mean meal prices are not all the same for the three types of restaurants.
b)Reject H0. There is sufficient evidence to conclude that the mean meal prices are not all the same for the three types of restaurants.
c)Do not reject H0. There is sufficient evidence to conclude that the mean meal prices are not all the same for the three types of restaurants.
d)Reject H0. There is not sufficient evidence to conclude that the mean meal prices are not all the same for the three types of restaurants

HURRY I NEED HELP!!! 60 points!!!!
Which of the following are like terms?

Answers
Answer:
b
Step-by-step explanation:
they all have y AND NO POWERS (x^2 is different to x)
How to convert 95 confidence z score?
Answers
The z-score associated with a 95% confidence level is approximately 1.96.
The z-score associated with a 95% confidence level is the value of the standard normal distribution that corresponds to an area of 0.95 to the left of the z-score.
Using a standard normal distribution table or calculator, we can find that the z-score associated with a 95% confidence level is approximately 1.96.
Therefore, if we want to calculate the z-score for a 95% confidence level, we can use the formula
z = invNorm(1 - α/2)
where α is the significance level (α = 0.05 for a 95% confidence level), and inv Norm is the inverse normal cumulative distribution function. Using this formula, we can calculate the z-score as:
z = inv Norm(1 - 0.05/2)
= inv Norm(0.975) ≈ 1.96
Therefore, the z-score is 1.96
Learn more about z-score here
brainly.com/question/15016913
#SPJ4
Let's say someone is conducting research on whether people in the community would attend a pride parade. Even though the population in the community is 95% straight and 5% lesbian, gay, or some other queer identity, the researchers decide it would be best to have a sample that includes 50% straight and 50% LGBTQ+ respondents. This would be what type of sampling?
A. Disproportionate stratified sampling
B. Availability sampling
C. Snowball sampling
D. Simple random sampling
Answers
The type of sampling described, where the researchers intentionally select a sample with 50% straight and 50% LGBTQ+ respondents, is known as "disproportionate stratified sampling."
A. Disproportionate stratified sampling involves dividing the population into different groups (strata) based on certain characteristics and then intentionally selecting a different proportion of individuals from each group. In this case, the researchers are dividing the population based on sexual orientation (straight and LGBTQ+) and selecting an equal proportion from each group.
B. Availability sampling (also known as convenience sampling) refers to selecting individuals who are readily available or convenient for the researcher. This type of sampling does not guarantee representative or unbiased results and may introduce bias into the study.
C. Snowball sampling involves starting with a small number of participants who meet certain criteria and then asking them to refer other potential participants who also meet the criteria. This sampling method is often used when the target population is difficult to reach or identify, such as in hidden or marginalized communities.
D. Simple random sampling involves randomly selecting individuals from the population without any specific stratification or deliberate imbalance. Each individual in the population has an equal chance of being selected.
Given the description provided, the sampling method of intentionally selecting 50% straight and 50% LGBTQ+ respondents represents disproportionate stratified sampling.
To learn more about stratified sampling Click Here: brainly.com/question/30397570
#SPJ11
Help me please 3/7 - 1/2
Answers
Which branch of statistics would employ probability to predict how many miles one should be able to drive a 2000 toyota celica during its lifetime?
Answers
The inferential statistics would employ the probability to predict how many miles one should be able to drive a 2000 Toyota Celica during its lifetime.
What is inferential statistics?The branch of statistics that deals with the sample data to predict or generalize the larger data is inferential statistics.This statistic is based on the probability theory.How the inferential statistics are predicted?The inferential statistics are calculated by using analytical tools such as test-statistic values, degree of freedom, sample size, and the rejection criteria(assumption or hypothesis).
Thus, the given information is about predicting the miles. So, according to the probability theory, it needs a sample of data about 2000 Toyota Celica.
Hence, it falls under the inferential branch of statistics. So, option C is correct.
Learn more about inferential statistics here:
https://brainly.com/question/1603975
#SPJ4
Disclaimer: The given question on the portal was incomplete. Here is the complete question.
Question: Which branch of statistics would employ probability to predict how many miles one should be able to drive a 2000 Toyota Celica during its lifetime?
A. Predictive statistics
B. Descriptive statistics
C. Inferential statistics
D. Differential statistics
Suppose a business records the following values each day the total number of customers that day (X) Revenue for that day (Y) A summary of X and Y in the previous days is mean of X: 600 Standard deviation of X: 10 Mean of Y: $5000, Standard deviation of Y: 1000 Correlation r= 0.9 Calculate the values A,B,C and D (1 mark) Future value of X Z score of X Predicted y average of y+ r* (Z score of X)* standard deviation of y 595 A B 600 0 $5000 D 615 IC You will get marks for each correct answer but note you are encouraged to show working. If the working is correct but the answer is wrong you will be given partial marks
Answers
The predicted values of A, B, C, and D are: A = 595B = -0.5C = 600D = $6350, therefore, the correct option is IC.
Given,
Mean of X = 600
Standard deviation of X = 10
Mean of Y = $5000
Standard deviation of Y = 1000
Correlation r= 0.9
Future value of X = 595
Z score of X = (X- Mean of X) / Standard deviation of X= (595-600) / 10 = -0.5
Using the formula, Predicted y = average of y+ r* (Z score of X)* standard deviation of y
Predicted y = $5000 + 0.9 * (-0.5) * 1000 = $4750
The predicted value of Y for X = 595 is $4750.
Now, to find the values of A, B, C, and D; we need to calculate the Z score of X = 615 and find the corresponding predicted value of Y.
Z score of X = (X- Mean of X) / Standard deviation of X= (615-600) / 10 = 1.5
Predicted y = average of y+ r* (Z score of X)* standard deviation of y
Predicted y = $5000 + 0.9 * (1.5) * 1000 = $6350
The predicted value of Y for X = 615 is $6350.
Hence, the values of A, B, C, and D are: A = 595B = -0.5C = 600D = $6350
Therefore, the correct option is IC.
learn more about predicted value here:
https://brainly.com/question/29745404
#SPJ11
please help if you can!

Answers
Answer:
y = (2/3)x + 3
Step-by-step explanation:
Notice that if we start at any x value shown in the table and increase x by 3, y will increase by 2. Thus, the slope of the line is 2/3.
From the entry (0, 3), we know that the y-intercept is b = 3.
Thus, y = mx + b becomes:
y = (2/3)x + 3
What is the domain of this graph?

Answers
Answer:
(-3,-2,-1,1,2,3,4]
Step-by-step explanation:
All x values. Put the bracket and ( as well.
Help me plssssssssssssss

Answers
Answer:
2÷ 1/3 =6
3 ÷1/2=6
4÷2/3=6
4 ÷1/2=8
12÷3/2=8
Step-by-step explanation:
Hope this helps!
Find the exact values of x and y.

Answers
13 and 13√2 is the value of x and y in the given diagram
Trigonometry identityThe given diagram is a right triangle, we need to determine the value of x and y.
Using the trigonometry identity
tan45 = opposite/adjacent
tan45 = x/13
x = 13tan45
x = 13(1)
x = 13
For the value of y
sin45 = x/y
sin45 = 13/y
y = 13/sin45
y = 13√2
Hence the exact value of x and y from the figure is 13 and 13√2 respectively.
Learn more on trigonometry identity here: https://brainly.com/question/24496175
#SPJ1
What is function and not function?
Answers
Answer: A function is a relation between domain and range such that each value in the domain corresponds to only one value in the range. Relations that are not functions violate this definition. They feature at least one value in the domain that corresponds to two or more values in the range.
Step-by-step explanation:
Normal probability distribution is applied to: A. a subjective random variable B. a discrete random variable C. any random variable D. a continuous random variable
Answers
Normal probability distribution is applied to a continuous random variable. The correct option is D.
The normal probability distribution, also known as the Gaussian distribution, is a probability distribution that is commonly used in statistics and probability theory. It is a continuous probability distribution that is often used to model the behavior of a wide range of variables, such as physical measurements like height, weight, and temperature.
The normal distribution is characterized by two parameters: the mean (μ) and the standard deviation (σ). It is a bell-shaped curve that is symmetrical around the mean, with the highest point of the curve being located at the mean. The standard deviation determines the width of the curve, and 68% of the data falls within one standard deviation of the mean, while 95% falls within two standard deviations.
The normal distribution is widely used in statistical inference and hypothesis testing, as many test statistics are approximately normally distributed under certain conditions. It is also used in modeling various phenomena, including financial markets, population growth, and natural phenomena like earthquakes and weather patterns.
Overall, the normal probability distribution is a powerful tool for modeling and analyzing a wide range of continuous random variables in a variety of fields.
To learn more about continuous random variable refer here:
https://brainly.com/question/17238189
#SPJ11
Acellus. Solve for x. x = ?

Answers
Answer:
according to basic proportionality theorem
\(\qquad\sf {:}\longrightarrow 25/35=x/63 \)
\(\qquad\sf {:}\longrightarrow 5/7=x/63\)
\(\qquad\sf {:}\longrightarrow 7x=63×5=315 \)
\(\qquad\sf {:}\longrightarrow x=315/7=45 \)
HELP ME ASAP ILL GIVE YOU BRAINLIEST!

Answers
Ok. To convert anything into anything else you do something very very simple. Divide what you want...by what you have. For example, if I have 15 liters of water, I'm going to multiply by gallons over liters. Multiply the measurement given by what you want, then divide that by what you have.
You take the higher unit and make that 1, then however many of the other units you can fit and that's the other number. That can become 1 gallon / 3.79 liters, or 30m / 3000cm, etc.
So you have 15 liters, you want it in gallons, and it takes four gallons per liter:
15 liters x 1 / 3.79
= 4 gallons (3.9577836 gallons unrounded)
This works because you are dividing the measurement given by how many units of that measurement it takes to fit in another measurement. However, I prefer this method because it makes it easier to figure out when to multiply into smaller units, or divide to get bigger units.
How to convert: measurement x want / have
a grocery can buy strawberries for $1.38 per pound write an equation relation the cost and the pounds of strawberries
Answers
Answer:
y=1.38x
Step-by-step explanation:
there are four copy machines in the library. it is estimated that the probability that a particular copy machine is out of order is 0.3. assuming that the machines work independently of each other what is the probability that at least one machine is out of order the next time you go to the library?
Answers
Answer:
≅ 0.76 or 76%
Step-by-step explanation:
To find the probability that at least one copy machine is out of order, we can use the complement rule. That is, we can find the probability that none of the copy machines are out of order, and then subtract that from 1.
The probability that a particular copy machine is working is 1 - 0.3 = 0.7. Since we have four copy machines that work independently of each other, the probability that all four machines are working is:
0.7 x 0.7 x 0.7 x 0.7 = 0.2401
So the probability that none of the copy machines are out of order is 0.2401.
Therefore, the probability that at least one machine is out of order is:
1 - 0.2401 = 0.7599
So the probability that at least one copy machine is out of order is approximately [0.76, or 76%.]
Volume of a cube (cm') = width (cm) x height (cm) x length (cm). 1.1) Using the equation above, determine the volume of a cube that measures 3 cm wide, 3 cm tall, and 3 cm long. 1.2) Let's say this cube is made out of ice and has a mass of 24.76 grams (g). What is this ice cube's density? 1.3) The density of liquid water is slightly higher than that of frozen water ice. Liquid water's density at standard pressures and temperatures is 1.00 grams per cubic centimeter (g/cm'). Given that density, what is the mass of a cube of water measuring 3 cm wide, 3 cm tall, and 3 cm long? 1.4) Compare the weight of the water you calculated in question 1.3 with the weight of the ice of the same volume given in question 1.2. Which is heavier, the liquid water or the ice? Notice that the cube of water is the same size (or volume) as the cube of ice. 1.5) You know that ice floats on water. Explain why.
Answers
1.1) The volume of the cube is 27 cubic centimeters. 1.2)the density of the ice cube is approximately 0.917 grams per cubic centimeter (g/cm³).
1.3) the mass of the water cube is 27 grams. 1.4) the weight of the water and the ice would be the same under the same conditions. 1.5)In simpler terms, ice floats on water because it is lighter (less dense) than the water, allowing it to displace an amount of water equal to its weight and float on the surface.
1.1) The volume of the cube can be calculated using the equation: Volume = width x height x length. In this case, the cube measures 3 cm wide, 3 cm tall, and 3 cm long, so the volume is:
Volume = 3 cm x 3 cm x 3 cm = 27 cm³.
Therefore, the volume of the cube is 27 cubic centimeters.
1.2) Density is defined as mass divided by volume. The mass of the ice cube is given as 24.76 grams, and we already determined the volume to be 27 cm³. Therefore, the density of the ice cube is:
Density = Mass / Volume = 24.76 g / 27 cm³ ≈ 0.917 g/cm³.
Therefore, the density of the ice cube is approximately 0.917 grams per cubic centimeter (g/cm³).
1.3) The volume of the water cube is the same as the ice cube, which is 27 cm³. Given the density of liquid water as 1.00 g/cm³, we can calculate the mass of the water cube using the equation:
Mass = Density x Volume = 1.00 g/cm³ x 27 cm³ = 27 grams.
Therefore, the mass of the water cube is 27 grams.
1.4) The weight of an object depends on both its mass and the acceleration due to gravity. Since the volume of the water cube and the ice cube is the same (27 cm³), and the mass of the water cube (27 grams) is equal to the mass of the ice cube (24.76 grams), their weights would also be equal when measured in the same gravitational field.
Therefore, the weight of the water and the ice would be the same under the same conditions.
1.5) Ice floats on water because it is less dense than liquid water. The density of ice is lower than the density of water because the water molecules in the solid ice are arranged in a specific lattice structure with open spaces. This arrangement causes ice to have a lower density compared to liquid water, where the molecules are closer together.
When ice is placed in water, the denser water molecules exert an upward buoyant force on the less dense ice, causing it to float. The buoyant force is the result of the pressure difference between the top and bottom surfaces of the submerged object.
In simpler terms, ice floats on water because it is lighter (less dense) than the water, allowing it to displace an amount of water equal to its weight and float on the surface.
Learn more about cube;
brainly.com/question/15420947
#SPJ4
when comparing two sample means, we can safely reject the null hypothesis if ______.
Answers
When comparing two sample means, we can safely reject the null hypothesis if the calculated test statistic exceeds the critical value corresponding to the chosen significance level.
In hypothesis testing, when comparing two sample means, we typically perform a t-test or z-test depending on the characteristics of the data and assumptions. The null hypothesis assumes that there is no significant difference between the means of the two samples.
To determine whether we can reject the null hypothesis and conclude that there is a significant difference, we calculate a test statistic. The specific test statistic (t or z) depends on factors such as sample size and whether population parameters are known.
Next, we compare the calculated test statistic to the critical value. The critical value is determined based on the chosen significance level (commonly denoted as α). If the calculated test statistic exceeds the critical value, we reject the null hypothesis, indicating that there is evidence to support a significant difference between the two sample means.
The significance level determines the threshold for rejecting the null hypothesis and is typically set at 0.05 (5%) or lower, depending on the desired level of confidence.
To know more about null hypothesis, refer here:
https://brainly.com/question/30535681
#SPJ11
the legend on the map states that 1 cm is 15 km. if you measure 11 cm on the map, how many kilometers would the actual distance be?
Answers
Answer:
165 km
Step-by-step explanation:
We know the ratio of map distance to actual distance is 1 cm : 15 km
Multiplying both sides by 11, we have 11 cm : 165 km
The radius of a circle is 12.8m. Find the circumference to the nearest tenth
Answers
Answer:
80.4
Step-by-step explanation:
The radius is 12.8m so to find circumference we have to multiply it by 2, 12.8x2 equals 25.6. Since we find our diameter we multiply 25.6 by pie or 3.14 and we 80.384 and round to the tenths place. Which is 80.4
if a tap fills a 450 litres tank with water in 1 hour, the water flows at the rate of _________ litres per minute
Answers
2 x 6/7
SEND HELP!!!!!!!!!!!

Answers
Answer: C. 2 6/7
Hope that helped! :)